Wdrażanie modeli AI bez porządnego procesu zwykle kończy się podobnie: eksperyment działa w notebooku, ale produkcja zaczyna się rozjeżdżać przy pierwszej zmianie danych, ruchu albo wymagań biznesu. W tym artykule pokazuję, czym są operacje dla uczenia maszynowego, jak wygląda pełny cykl życia modelu, które praktyki naprawdę stabilizują pracę zespołu i po jakie narzędzia warto sięgnąć. Dorzucam też błędy, które najczęściej kosztują czas, budżet i zaufanie do modelu.
Najważniejsze rzeczy o MLOps w skrócie
- MLOps łączy rozwój modeli, automatyzację wdrożeń i utrzymanie w produkcji.
- Największą różnicę robią: wersjonowanie danych i modeli, pipeline’y, monitoring oraz jasne zasady odpowiedzialności.
- Dobry proces zaczyna się od jednego use case’u, a nie od wyboru narzędzia.
- Modele trzeba monitorować po wdrożeniu, bo nawet dobry model traci jakość, gdy zmieniają się dane wejściowe.
- Narzędzia są ważne, ale bez governance, testów i właściciela modelu nie dają trwałego efektu.
Czym jest MLOps i po co w ogóle go wdrażać
MLOps to zestaw praktyk i narzędzi, które porządkują cały cykl życia modelu uczenia maszynowego: od danych, przez trening i testy, po wdrożenie, monitoring i ponowne trenowanie. W praktyce chodzi o to, żeby model nie był jednorazowym eksperymentem, tylko elementem systemu, który da się powtarzalnie budować, kontrolować i rozwijać.
Największa różnica między zwykłym projektem ML a dojrzałym podejściem operacyjnym pojawia się wtedy, gdy model trzeba utrzymać w ruchu przez miesiące, a nie tylko pokazać na demo. Bez procesu szybko wychodzą te same problemy: brak reprodukowalności wyników, ręczne wdrożenia, chaos wersji danych, brak historii eksperymentów i opóźniona reakcja na spadek jakości.
Z mojego doświadczenia ten temat szczególnie dobrze widać tam, gdzie AI wpływa na realne decyzje: w e-commerce, finansach, logistyce, produkcji albo obsłudze klienta. Tam model nie może być „ładny na papierze” - musi działać stabilnie, być audytowalny i dawać się wycofać, gdy coś pójdzie nie tak. Kiedy to rozdzielisz, łatwiej zobaczyć, że model nie jest gotowy po treningu, tylko dopiero wtedy, gdy da się go bezpiecznie utrzymać w ruchu.
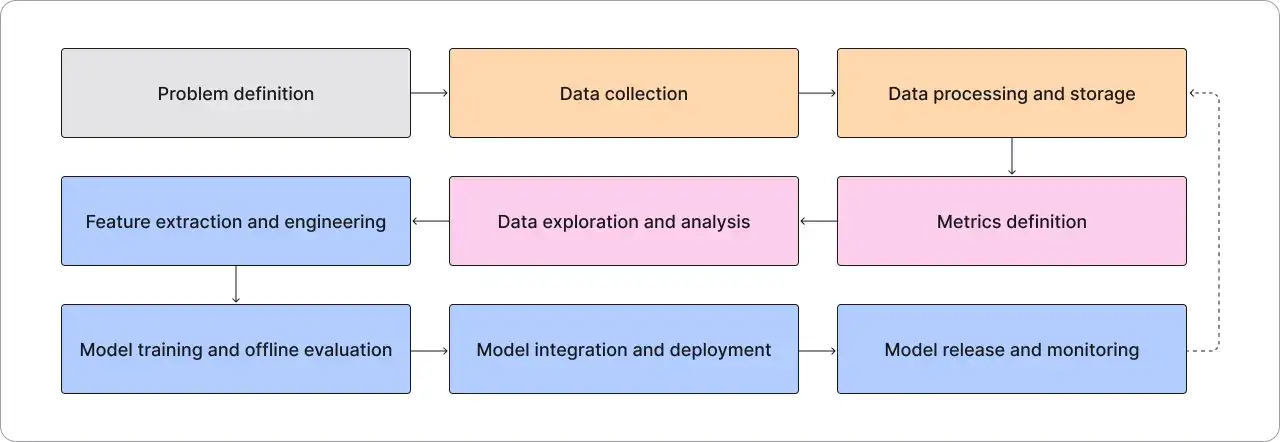
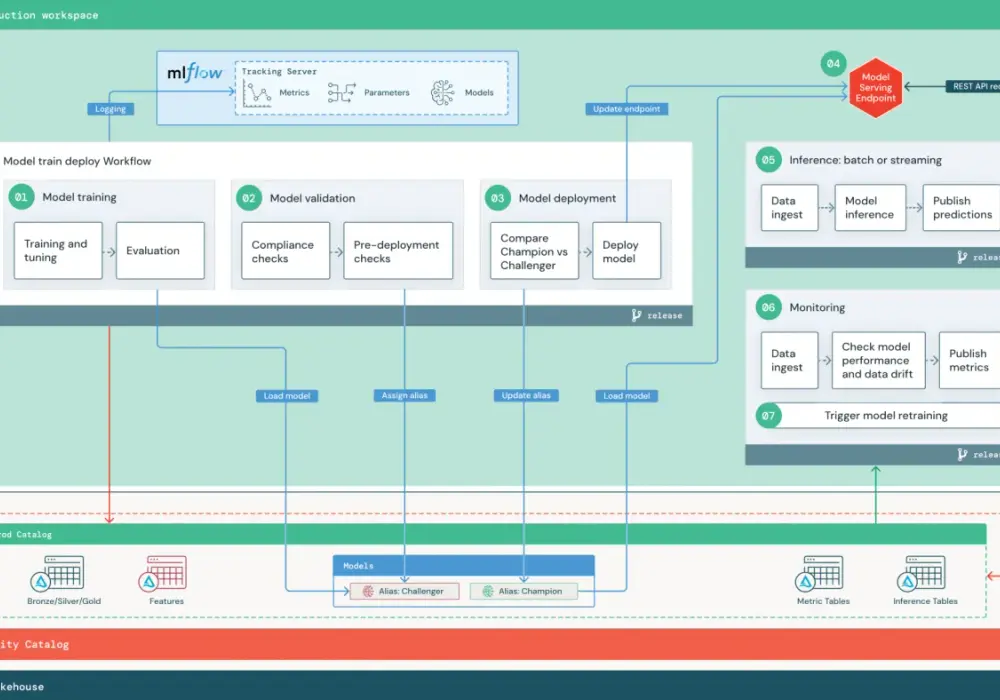
Jak wygląda cykl życia modelu od danych do monitoringu
Jeśli mam uprościć temat do jednego zdania, to cykl życia modelu wygląda tak: najpierw porządkujesz dane, potem trenujesz i walidujesz model, następnie wdrażasz go do środowiska produkcyjnego, a później stale sprawdzasz, czy nadal spełnia swoje zadanie. Właśnie w tym łańcuchu najczęściej psuje się cały projekt, dlatego nie warto traktować go jak jednorazowego sprintu.
- Przygotowanie danych - czyszczenie, walidacja, standaryzacja i tworzenie cech wejściowych. Na tym etapie najłatwiej zepsuć cały projekt, jeśli dane są niepełne albo niespójne.
- Trening i eksperymenty - testowanie wielu wariantów modelu, parametrów i cech. Tu kluczowe jest śledzenie, co dokładnie dało dany wynik.
- Walidacja - sprawdzenie jakości na danych, których model nie widział podczas treningu. Bez tego łatwo pomylić dopasowanie do treningu z prawdziwą skutecznością.
- Rejestracja modelu - zapisanie wersji modelu, metryk, zależności i artefaktów. To daje możliwość cofnięcia się do poprzedniej, sprawdzonej wersji.
- Wdrożenie - publikacja modelu jako usługi online, batch jobu albo komponentu w aplikacji. Dobór zależy od tego, jak model ma być używany.
- Monitoring i retrening - obserwacja jakości predykcji, driftu danych i zmian w zachowaniu użytkowników. Gdy warunki się zmieniają, model trzeba aktualizować.
Dwa pojęcia, które pojawiają się tu najczęściej, to drift danych i training-serving skew. Drift oznacza, że dane produkcyjne zaczynają różnić się od tych, na których model był trenowany. Skew to z kolei rozjazd między tym, jak dane wyglądają w treningu, a jak są przygotowywane przy inferencji. Oba zjawiska potrafią cicho obniżać jakość modelu, nawet jeśli sam kod się nie zmienił.
Dopiero na takim szkielecie widać, które praktyki naprawdę zmniejszają ryzyko i przyspieszają pracę zespołu.
Które praktyki dają największy zwrot
Nie każdy element procesu ma taki sam wpływ na efekt końcowy. Gdybym miał wybrać kilka rzeczy, które naprawdę robią różnicę, zacząłbym od tych poniżej.
| Praktyka | Po co jest | Co wdrożyć na start | Typowy błąd |
|---|---|---|---|
| Wersjonowanie kodu, danych i modeli | Umożliwia odtworzenie wyniku i cofnięcie zmian | Git, identyfikatory datasetów, registry modeli | Trzymanie tylko kodu bez historii danych |
| Śledzenie eksperymentów | Pokazuje, która konfiguracja faktycznie działa | Metryki, parametry, artefakty, notatki z testów | Porównywanie wyników z pamięci albo arkusza |
| Pipeline’y CI/CD | Automatyzują testy, trening i wdrożenie | Automatyczny trening po zmianie kodu lub danych | Ręczne przeklikiwanie kolejnych etapów |
| Monitoring produkcyjny | Wykrywa spadek jakości, drift i anomalie | Alerty na metryki techniczne i biznesowe | Patrzenie tylko na metryki techniczne bez kontekstu biznesowego |
| Feature store | Ujednolica cechy używane w treningu i inferencji | Wspólny magazyn cech dla zespołów i usług | Ręczne kopiowanie logiki feature engineeringu |
| Governance i akceptacje | Porządkuje odpowiedzialność, zgodność i audyt | Właściciel modelu, proces zatwierdzeń, log audytowy | Brak jasnego procesu zatwierdzania zmian |
W praktyce feature store to centralne miejsce, w którym przechowuje się i udostępnia cechy używane przez modele. Dzięki temu te same transformacje nie muszą być ręcznie odtwarzane w kilku miejscach, a ryzyko rozjazdu między treningiem i produkcją mocno spada.
Jeśli miałbym wskazać jedną zasadę, byłaby prosta: najpierw uporządkuj powtarzalność, dopiero potem skaluj ambicje. Gdy te elementy są poukładane, dopiero wtedy wybór technologii przestaje być zgadywaniem, a staje się decyzją architektoniczną.
Jakie narzędzia wybiera się w praktyce
Nie ma jednego uniwersalnego stosu. Dobór narzędzi zależy od tego, czy budujesz rozwiązanie w chmurze, czy opierasz się na open source, jak duży masz zespół i ile kontroli chcesz zachować nad infrastrukturą. Ja zwykle zaczynam od kategorii, a nie od marki.
| Obszar | Przykładowe narzędzia | Kiedy pasują najlepiej | Na co uważać |
|---|---|---|---|
| Orkiestracja pipeline’ów | Airflow, Kubeflow, Prefect | Gdy proces ma wiele kroków i zależności | Zbyt złożona konfiguracja na sam start |
| Tracking i rejestr modeli | MLflow, Vertex AI Experiments, Azure ML | Gdy zespół testuje wiele wariantów modelu | Brak dyscypliny w logowaniu metryk i artefaktów |
| Feature store | Feast, usługi natywne w chmurze | Gdy cechy są współdzielone między projektami | Wdrażanie go bez rzeczywistej potrzeby współdzielenia |
| Monitoring modeli | Evidently, monitorowanie wbudowane w platformy chmurowe | Gdy ważny jest drift, jakość i alerty | Monitorowanie tylko uptime, a nie jakości modelu |
| Serving i inferencja | BentoML, KServe, SageMaker, Vertex AI, Azure ML | Gdy model ma działać jako API albo batch | Wybór rozwiązania bez myślenia o latency i kosztach |
| Wersjonowanie danych | DVC, lakeFS, narzędzia platformowe | Gdy dane zmieniają się często i trzeba je odtwarzać | Traktowanie danych jak zwykłych plików bez historii |
Widać tu wyraźny podział: open source daje większą elastyczność, ale wymaga silniejszego zespołu platformowego, a rozwiązania chmurowe skracają czas startu kosztem większej zależności od ekosystemu dostawcy. To nie jest spór ideologiczny, tylko praktyczny wybór między kontrolą, tempem wdrożenia i kosztem utrzymania.
Ale nawet najlepszy stack nie uratuje projektu, jeśli proces od początku ma złe założenia, więc właśnie tam zwykle szukam problemów.
Najczęstsze błędy, które psują projekt
W projektach AI widzę kilka pułapek tak regularnie, że można je uznać za klasykę. Problem polega na tym, że większość z nich nie wygląda groźnie na starcie.
- Zaczynanie od narzędzia - zespół wybiera platformę, zanim ustali, jaki problem biznesowy rozwiązuje model.
- Brak wersjonowania danych - model da się odtworzyć tylko pozornie, bo nie wiadomo, na jakim zbiorze był trenowany.
- Brak właściciela modelu - nikt nie odpowiada za metryki, alerty i decyzję o retreningu.
- Mylenie jakości treningowej z produkcyjną - świetny wynik offline nie oznacza dobrej pracy na realnych danych.
- Za późny monitoring - alerty pojawiają się dopiero wtedy, gdy użytkownicy już odczuli spadek jakości.
- Brak planu wycofania modelu - gdy coś się psuje, zespół nie ma bezpiecznego rollbacku ani wersji awaryjnej.
- Ignorowanie zgodności i bezpieczeństwa - dostęp do danych, modeli i logów bywa potraktowany jako detal, a to potem wraca w audycie.
Najbardziej zdradliwy błąd to ten ostatni etap: model jest już wdrożony, więc zespół uznaje, że projekt „działa”. Tymczasem dopiero wtedy zaczyna się prawdziwa odpowiedzialność za jakość, koszty i ryzyko. Kiedy te pułapki masz z głowy, można przejść z myślenia o platformie do planu wdrożenia krok po kroku.
Jak zacząć bez przepalania budżetu
Jeśli zespół nie ma jeszcze dojrzałej platformy, nie ma sensu budować wszystkiego naraz. Ja zwykle rekomenduję podejście od jednego, dobrze wybranego use case’u. Pierwszy sensowny pilot da się zwykle postawić w 4-8 tygodni, jeśli podstawowa infrastruktura już istnieje; pełniejsza dojrzałość procesu to raczej kilka miesięcy, a nie jeden sprint.
- Wybierz jeden przypadek użycia - najlepiej taki, w którym sukces da się zmierzyć biznesowo, a dane są już dostępne.
- Ustal metryki od początku - osobno techniczne i biznesowe, bo same AUC czy accuracy nie mówią jeszcze, czy model realnie pomaga.
- Zbuduj minimalny pipeline - wersjonowanie, trening, test, rejestracja i wdrożenie to dobry punkt startu.
- Dodaj monitoring po wdrożeniu - nie czekaj na pierwszą awarię, tylko ustaw alerty na jakość danych i wyników.
- Zdefiniuj retrening - określ, kiedy model ma być ponownie trenowany: po zmianie danych, spadku metryk lub zmianie zachowania użytkowników.
- Ustal odpowiedzialność - ktoś musi pilnować modelu, nawet jeśli cały zespół uczestniczy w jego budowie.
W małych zespołach największy zwrot daje nie „pełna platforma”, tylko dobrze spięty minimalny proces. Wtedy rośnie przewidywalność, a nie liczba abstrakcyjnych komponentów. Na koniec zostaje jeszcze jedna rzecz: co musi być ustalone, zanim model trafi do realnych użytkowników.
Co ustalić przed produkcją, żeby model nie stał się ryzykiem
Zanim model trafi do produkcji, sprawdziłbym przede wszystkim cztery obszary: odpowiedzialność, odtwarzalność, monitoring i plan awaryjny. Bez tego nawet dobry model może stać się źródłem kosztów zamiast wartości.
- kto jest właścicielem modelu i kto reaguje na alerty,
- jak szybko da się wrócić do poprzedniej wersji,
- jakie dane i metryki są logowane,
- co uruchamia retrening albo wycofanie modelu,
- czy dostęp do danych i modeli jest zgodny z wymaganiami bezpieczeństwa i audytu.
Jeśli te elementy są gotowe, model ma szansę działać jako stabilna część produktu, a nie jednorazowy eksperyment opakowany w ładną prezentację. To właśnie dlatego dobrze ustawiony MLOps nie jest dodatkiem do AI, tylko warunkiem, żeby cała inicjatywa miała sens w produkcji.