Modele językowe zmieniły sposób, w jaki korzystamy z AI: potrafią pisać, streszczać, tłumaczyć, kodować i odpowiadać na pytania w naturalnym języku. Problem w tym, że łatwo potraktować je jak inteligentny czat, a to zbyt płytkie ujęcie. W tym tekście wyjaśniam, czym naprawdę są modele LLM, jak działają, gdzie dają największą wartość i jakie ryzyka trzeba uwzględnić, jeśli chcesz używać ich sensownie w biznesie albo w codziennej pracy technicznej.
Najważniejsze informacje o modelach językowych w praktyce
- Model językowy nie „wie” rzeczy jak człowiek, tylko przewiduje kolejne tokeny na podstawie kontekstu i wzorców z danych treningowych.
- Największą wartość daje tam, gdzie trzeba szybko pracować z tekstem: analizować dokumenty, tworzyć szkice, wspierać obsługę klienta, kodować i wyszukiwać informacje.
- RAG pomaga podpiąć aktualne lub firmowe dane, żeby odpowiedzi były bardziej trafne niż przy samym modelu wytrenowanym wcześniej.
- Największe ryzyka to halucynacje, błędy faktograficzne, prywatność danych, koszty przy dużej skali i ograniczone okno kontekstu.
- Najlepsze wdrożenia nie zaczynają się od „jakiego chatbota kupić”, tylko od konkretnego procesu, mierzalnego celu i zasad kontroli jakości.
Czym są modele językowe i dlaczego stały się tak ważne
Najprościej mówiąc, model językowy to system uczony na ogromnych zbiorach tekstu, który przewiduje kolejne tokeny, czyli fragmenty słów albo słowa, na podstawie kontekstu. To dlatego potrafi generować naturalne odpowiedzi, ale nie „wie” czegoś w ludzkim sensie. Ma wzorce, statystyczną pamięć zależności i umiejętność składania ich w sensowny tekst.
W praktyce oznacza to, że dobry model LLM nie jest encyklopedią, tylko silnikiem do przetwarzania języka, który trzeba dobrze ustawić, nakarmić właściwym kontekstem i kontrolować. Ja patrzę na niego jak na bardzo szybki, ale podatny na błędy komponent do pracy z informacją. Z tego powodu najlepsze efekty pojawiają się tam, gdzie AI przyspiesza pracę człowieka, a nie udaje nieomylnego eksperta. To rozróżnienie ma znaczenie, bo od niego zależy sposób wdrożenia i oczekiwania wobec systemu.
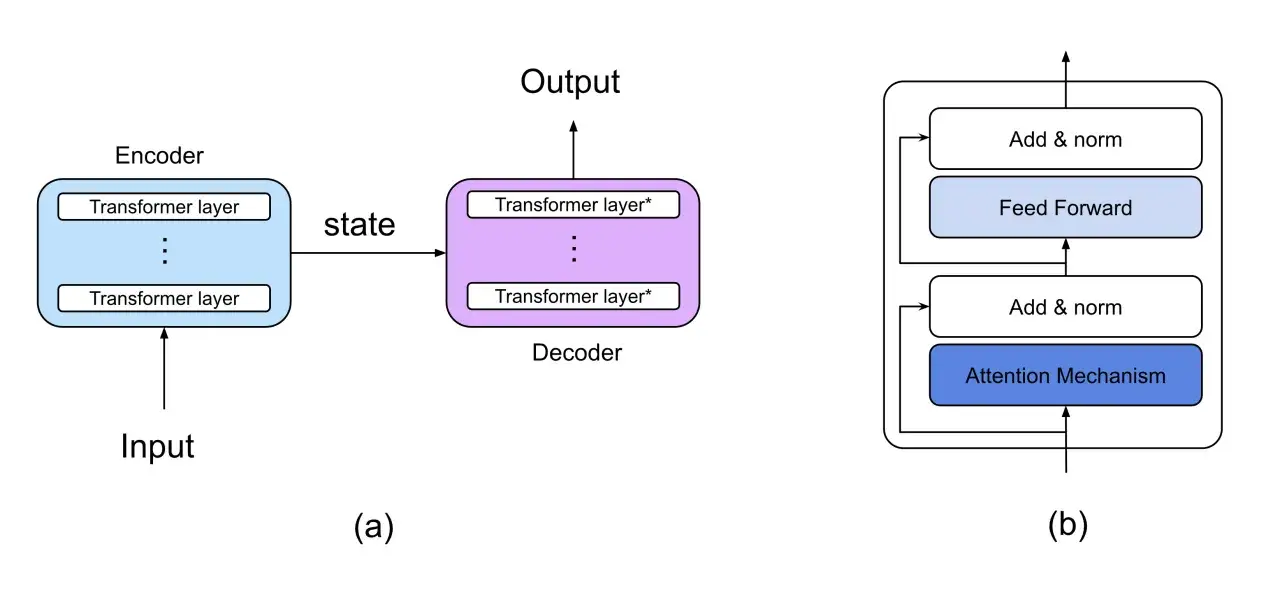
Jak działają pod maską
Od strony technicznej model dzieli tekst na tokeny, zamienia je na reprezentacje liczbowe i analizuje relacje między nimi w warstwach transformera. Mechanizm uwagi pozwala mu ocenić, które fragmenty wejścia są ważniejsze dla danego pytania albo zdania. To właśnie dlatego model może podtrzymywać sens rozmowy, a nie tylko dopasowywać pojedyncze słowa.
Tokeny i okno kontekstu
Token nie jest tym samym co słowo. Jeden wyraz może składać się z kilku tokenów, a krótsze elementy języka bywają łączone w różny sposób zależnie od modelu. Istotne jest także okno kontekstu, czyli ile tokenów model jest w stanie „widzieć” naraz. W praktyce spotyka się zakres od kilku tysięcy do setek tysięcy tokenów, dlatego dłuższe dokumenty trzeba często dzielić albo podawać w uporządkowanej formie.
Trening wstępny i dostrajanie
Wstępny trening uczy model wzorców językowych, a dostrajanie pomaga mu lepiej odpowiadać na konkretne zadania: obsługę klienta, analizę dokumentów, pisanie kodu albo pracę z instrukcjami. To ważne, bo sam duży model nie zawsze daje najlepszy efekt. Czasem mniejszy model z lepszym dostrojeniem i lepszym kontekstem wygrywa z większym, ale gorzej osadzonym rozwiązaniem.
Przeczytaj również: ChatGPT nie działa? Szybka diagnoza i naprawa krok po kroku
RAG zamiast zgadywania
Jeśli model ma odpowiadać na aktualne albo firmowe dane, często dodaje się RAG, czyli mechanizm pobierania trafnych fragmentów z bazy wiedzy i dopiero potem generowania odpowiedzi. To ogranicza problem zgadywania i zwiększa trafność, zwłaszcza w dokumentacji, regulaminach, bazach wiedzy i wewnętrznych procedurach. W praktyce to jeden z najważniejszych elementów wdrożeń, które mają działać stabilnie, a nie tylko imponować na demo.
Kiedy rozumie się tę architekturę, łatwiej ocenić, gdzie model ma sens, a gdzie będzie tylko efektowną warstwą nad słabym procesem. Następny krok to sprawdzenie, do jakich zadań naprawdę warto go używać.
Gdzie sprawdzają się najlepiej w praktyce
Największą wartość modele językowe dają tam, gdzie praca opiera się na tekście, wiedzy i powtarzalnych decyzjach. Nie chodzi wyłącznie o pisanie odpowiedzi na czacie. W dobrze zaprojektowanym środowisku mogą skrócić czas pracy zespołu, poprawić dostęp do wiedzy i odciążyć ludzi od zadań, które są monotonne, ale wymagają językowej precyzji.
- Obsługa klienta - model może odpowiadać na typowe pytania, klasyfikować zgłoszenia i podpowiadać konsultantom gotowe odpowiedzi. To działa najlepiej wtedy, gdy baza wiedzy jest aktualna i dobrze uporządkowana.
- Wsparcie dla programistów - generowanie szkiców kodu, wyjaśnianie błędów, tworzenie testów i przegląd logiki to obszary, w których AI oszczędza czas, ale nie zastępuje inżyniera.
- Streszczanie i ekstrakcja danych - model potrafi wyciągnąć z długiego dokumentu daty, nazwy, decyzje, punkty ryzyka albo wymagania, co przyspiesza pracę zespołów operacyjnych i prawnych.
- Wyszukiwanie semantyczne - zamiast szukać tylko po słowach kluczowych, można odnajdywać treści po znaczeniu. To szczególnie przydatne w dokumentacji technicznej i dużych repozytoriach wiedzy.
- Praca wielojęzyczna - tłumaczenia, lokalizacja treści i ujednolicanie stylu są dziś jednymi z najbardziej praktycznych zastosowań, zwłaszcza w firmach pracujących na kilku rynkach.
- Multimodalne scenariusze - coraz częściej modele radzą sobie nie tylko z tekstem, ale też z obrazami, wykresami i dokumentami skanowanymi. To otwiera drogę do automatyzacji pracy z fakturami, raportami i materiałami wizualnymi.
Wspólny mianownik jest prosty: model działa najlepiej tam, gdzie trzeba połączyć język, kontekst i szybkość. Gdy zadanie wymaga twardej odpowiedzialności lub aktualności co do minuty, trzeba już myśleć o ograniczeniach, a nie tylko o korzyściach.
Jakie ograniczenia trzeba brać pod uwagę
Największy błąd polega na założeniu, że skoro odpowiedź brzmi pewnie, to musi być prawdziwa. Właśnie tutaj modele językowe najczęściej zawodzą. Mogą wygenerować tekst płynny, logiczny i kompletnie błędny faktograficznie. Dlatego w praktyce ważniejsze od samej jakości „gadania” jest to, czy system potrafi pracować pod nadzorem, z walidacją i jasnymi granicami odpowiedzialności.
| Problem | Jak objawia się w praktyce | Co działa najlepiej |
|---|---|---|
| Halucynacje | Model odpowiada pewnie, ale podaje nieprawdziwe dane lub zmyślone szczegóły. | RAG, sprawdzanie odpowiedzi na źródłach, instrukcja przyznawania niepewności. |
| Stronniczość | Model powiela uprzedzenia albo nierówne traktowanie z danych treningowych. | Testy jakości, przegląd człowieka, filtrowanie ryzykownych odpowiedzi. |
| Prywatność | Do promptu trafiają dane wrażliwe, poufne lub objęte RODO. | Maskowanie danych, polityka dostępu, kontrola integracji i wybór odpowiedniej architektury. |
| Koszt i opóźnienie | Przy dużej skali odpowiedzi są droższe i wolniejsze. | Krótszy prompt, cache, mniejszy model do prostych zadań, batching. |
| Krótki kontekst | Model gubi wcześniejsze ustalenia, jeśli rozmowa albo dokument jest zbyt długi. | Dzielenie zadań, podsumowania pośrednie, indeksowanie i wyszukiwanie semantyczne. |
Ja zwykle zakładam, że każdy model będzie popełniał błędy, dopóki nie udowodni tego test. Taka postawa oszczędza rozczarowań i pozwala od razu projektować bezpieczniejszy proces. Skoro wiemy już, gdzie leżą pułapki, warto przejść do decyzji, jak w ogóle wdrażać takie rozwiązanie.
Jak wybrać podejście do wdrożenia
Nie ma jednego najlepszego scenariusza. Wybór zależy od tego, czy priorytetem jest koszt, kontrola nad danymi, szybkość wdrożenia, czy jakość odpowiedzi na specjalistycznym materiale. W polskich realiach szczególnie istotne są kwestie RODO, bezpieczeństwa danych i tego, czy system może pracować na treściach firmowych bez ryzyka niepożądanego ujawnienia informacji.
| Podejście | Kiedy ma sens | Plusy | Ograniczenia |
|---|---|---|---|
| API zewnętrzne | Gdy chcesz szybko wystartować i testować pomysł bez ciężkiej infrastruktury. | Najszybsze wdrożenie, wysoka jakość, łatwa integracja. | Mniejsza kontrola nad danymi i zależność od dostawcy. |
| Model open-source na własnej infrastrukturze | Gdy kluczowa jest kontrola, prywatność i możliwość pełnej konfiguracji. | Większa niezależność, lepsza kontrola środowiska i polityk bezpieczeństwa. | Większe wymagania operacyjne, utrzymaniowe i często sprzętowe. |
| RAG na bazie wiedzy | Gdy model ma odpowiadać na aktualne dokumenty, procedury lub wiedzę firmową. | Lepsza trafność, mniejsze ryzyko zmyślania, łatwiejsze aktualizacje wiedzy. | Wymaga dobrej struktury dokumentów i sensownego wyszukiwania. |
| Dostrajanie modelu | Gdy potrzebujesz stałego stylu, specjalnej terminologii albo określonego formatu odpowiedzi. | Lepsze dopasowanie do specyficznego zadania. | Wymaga danych treningowych i nie rozwiązuje problemu aktualnej wiedzy. |
Ja zwykle zaczynam od prostszego wariantu: API plus RAG i dobry proces walidacji. Dopiero gdy widzę stabilny przypadek użycia, sensowny wolumen i jasny zwrot z inwestycji, rozważam większe dostosowanie modelu albo własną infrastrukturę. To podejście jest mniej efektowne na papierze, ale dużo rozsądniejsze operacyjnie.
Jak pisać prompty i budować workflow, żeby wyniki były stabilne
W praktyce najlepsze prompty przypominają krótką specyfikację zadania, a nie luźną prośbę. Model potrzebuje roli, celu, kontekstu, ograniczeń i formatu odpowiedzi. Im bardziej niejednoznaczne polecenie, tym większa szansa, że wynik będzie zbyt ogólny albo po prostu nietrafiony.
- Określ rolę i zadanie - zamiast „napisz tekst”, lepiej powiedzieć, czego dokładnie oczekujesz, dla kogo i w jakim stylu.
- Dodaj kontekst - model powinien wiedzieć, na jakich danych ma pracować i czego nie wolno mu zakładać.
- Wymuś format - lista, tabela, JSON, krótkie akapity albo konkretny układ ułatwiają późniejszą automatyzację.
- Podaj przykłady - jeden lub dwa dobre wzorce często znaczą więcej niż długi opis.
- Poproś o sygnalizowanie niepewności - to ogranicza ryzyko, że model będzie udawał pewność tam, gdzie jej nie ma.
- Testuj na zestawie przykładów - ja zawsze sprawdzam model na kilku realistycznych przypadkach, a nie na jednym „ładnym” demo.
W dobrym workflow prompt jest tylko pierwszą warstwą. Dalej liczy się walidacja danych wejściowych, kontrola wyjścia, logowanie błędów i miejsce na człowieka w punktach krytycznych. Jeśli model ma generować treści publiczne, decyzje lub odpowiedzi dla klientów, bez tego łatwo o chaos. Z kolei dobrze zaprojektowany proces potrafi dać bardzo dobry efekt nawet bez najbardziej zaawansowanego modelu.
Na czym naprawdę opiera się sensowne użycie modeli językowych
W 2026 najlepsze wdrożenia nie zaczynają się od pytania, jaki model jest „najmocniejszy”, tylko od pytania, jaki proces trzeba usprawnić i gdzie potrzebna jest kontrola człowieka. To właśnie tam modele językowe pokazują największą wartość: przyspieszają pracę, porządkują wiedzę i redukują powtarzalne zadania, ale nie zdejmują odpowiedzialności z zespołu.
Jeśli miałbym zostawić jedną praktyczną radę, brzmiałaby tak: zacznij od jednego, dobrze opisanego przypadku użycia, zmierz jakość odpowiedzi, dopiero potem skaluj. Takie podejście daje najlepszy stosunek ryzyka do efektu i pozwala uniknąć sytuacji, w której technologia imponuje na pokazie, ale zawodzi w codziennej pracy. Właśnie dlatego modele językowe są dziś ważne nie dlatego, że potrafią mówić jak człowiek, tylko dlatego, że można je włączyć w realny proces i zrobić z nich użyteczne narzędzie.