
Dobrze wdrożona sieć CDN skraca drogę między serwerem a użytkownikiem, odciąża origin i poprawia stabilność strony przy ruchu z wielu lokalizacji. W praktyce to jedna z tych technologii, które widać dopiero wtedy, gdy witryna zaczyna ładować się zbyt wolno albo nie radzi sobie ze skokami odwiedzin. Poniżej rozkładam temat na czynniki pierwsze: jak to działa, kiedy ma sens, jak wybrać usługę i gdzie najczęściej popełnia się kosztowne błędy.
Najważniejsze rzeczy, które trzeba wiedzieć o sieci CDN
- CDN przechowuje kopie zasobów bliżej użytkownika, dzięki czemu strona ładuje się szybciej.
- Największy zysk daje przy plikach statycznych, ruchu międzynarodowym i dużych skokach odwiedzin.
- Nie zastępuje hostingu ani backendu, tylko odciąża je i poprawia dystrybucję treści.
- O efektach decydują głównie cache, TTL, reguły purge i poprawne nagłówki HTTP.
- Źle skonfigurowana warstwa edge może przyspieszyć stronę tylko pozornie i wprowadzić trudne do znalezienia błędy.
- Przy wyborze usługi ważniejsze od marki są: reguły cache, bezpieczeństwo, logi, koszty transferu i łatwość utrzymania.
Czym jest sieć CDN i dlaczego nie zastępuje hostingu
Ja tłumaczę to najprościej tak: hosting trzyma oryginał, a CDN dostarcza jego kopie z miejsc położonych bliżej odbiorcy. Tę warstwę buduje się po to, żeby użytkownik z Warszawy, Berlina czy Madrytu nie musiał za każdym razem łączyć się z jednym centralnym serwerem, jeśli nie ma takiej potrzeby.
W praktyce CDN obsługuje przede wszystkim zasoby, które da się bezpiecznie buforować: obrazy, arkusze stylów, JavaScript, część HTML, pliki wideo, a czasem także odpowiedzi API. Nie jest to zamiennik hostingu, bo to nadal origin pozostaje źródłem prawdy dla treści i logiki aplikacji. CDN działa raczej jak inteligentna warstwa pośrednia, która zmniejsza obciążenie zaplecza i przyspiesza dostarczanie treści.
To ważne rozróżnienie, bo wiele problemów wynika z mylenia tych ról. Jeśli backend generuje stronę bardzo wolno, CDN nie naprawi samego silnika, ale może skutecznie ograniczyć liczbę wizyt w originie i poprawić czas odpowiedzi dla części użytkowników. Z tego mechanizmu wynika też pytanie, jak dokładnie odbywa się cały przepływ żądań.
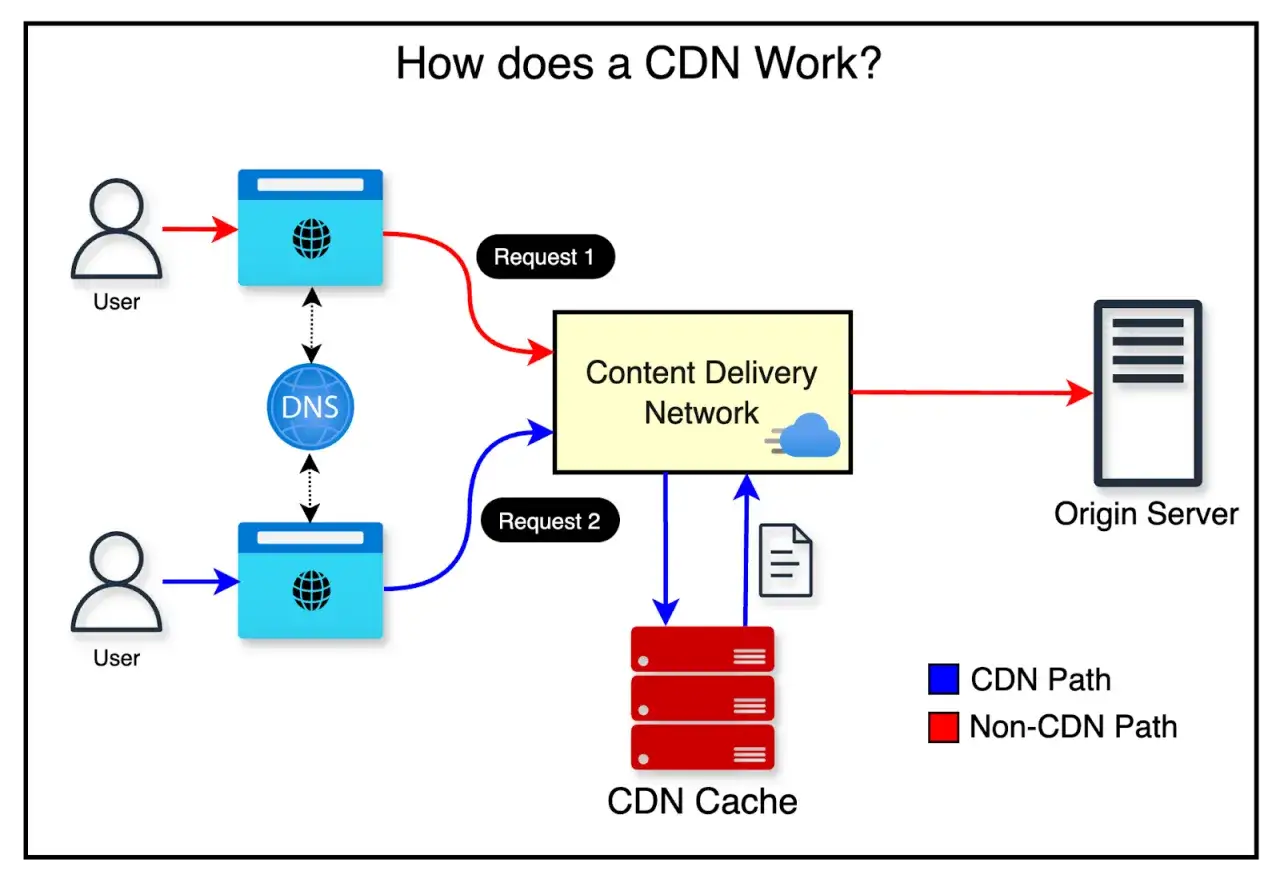
Jak działa CDN w praktyce
W uproszczeniu użytkownik wpisuje adres strony, a system kieruje go do najbliższego węzła edge, czyli punktu brzegowego sieci. To właśnie tam znajdują się kopie wielu plików, które można podać od ręki, bez odpytywania serwera źródłowego.
- Przeglądarka wysyła żądanie do domeny.
- DNS, routing Anycast lub logika dostawcy kieruje ruch do najbliższej lokalizacji edge.
- Węzeł sprawdza cache, czyli lokalną pamięć podręczną.
- Jeśli plik jest dostępny, odpowiedź wraca natychmiast.
- Jeśli pliku nie ma, edge pobiera go z originu, zapisuje i podaje użytkownikowi.
W tym miejscu zaczynają mieć znaczenie nagłówki HTTP. Cache-Control mówi, jak długo dana kopia może żyć, ETag i Last-Modified pomagają ocenić, czy zasób nie zmienił się od poprzedniego pobrania, a TTL określa czas ważności wpisu w cache. Przy plikach statycznych to zwykle prosta sprawa, ale przy treściach zależnych od sesji albo lokalizacji użytkownika trzeba już uważać dużo bardziej.
W nowoczesnych wdrożeniach dochodzi jeszcze kompresja, HTTP/2 lub HTTP/3 oraz czasem logika wykonywana na brzegu, np. przepisywanie nagłówków czy podpisywanie adresów. Dzięki temu cały mechanizm nie tylko skraca dystans sieciowy, ale też redukuje liczbę zbędnych połączeń. To prowadzi do pytania, kiedy taki układ daje realny zwrot, a kiedy jest tylko kolejną warstwą do utrzymania.
Kiedy daje największy efekt, a kiedy lepiej go odpuścić
Nie każda strona zyska na CDN w takim samym stopniu. Najwięcej wygrywają serwisy, które mają dużo ruchu z różnych regionów, sporo ciężkich plików statycznych albo skoki wejść po kampanii, publikacji lub wydarzeniu live.
| Sytuacja | Efekt CDN | Co warto obserwować |
|---|---|---|
| Sklep internetowy z obrazami produktów i ruchem z kilku krajów | Duży | TTFB, czas ładowania kart produktu, obciążenie originu |
| Portal informacyjny z nagłymi pikami odwiedzin | Duży | Cache hit ratio, stabilność przy skoku ruchu, liczba requestów do backendu |
| Publiczne API używane przez wiele aplikacji | Średni do dużego | Reguły cache dla odpowiedzi, kontrola nagłówków, limitowanie ruchu |
| Panel administracyjny po zalogowaniu | Mały | Bezpieczeństwo, brak cache dla danych per użytkownik, poprawność sesji |
| Mała strona firmowa z jednym rynkiem lokalnym i prostą treścią | Ograniczony | Czy koszt i złożoność są warte zysku |
Ja zwykle patrzę na trzy liczby: ilu użytkowników przychodzi spoza głównego rynku, jaki procent strony stanowią zasoby statyczne i jak często serwis ma skoki ruchu. Jeśli większość odpowiedzi jest mocno spersonalizowana i nie da się jej bezpiecznie buforować, korzyść maleje. Jeśli za to masz zdjęcia, arkusze stylów, skrypty i ruch z wielu miast, zysk bywa bardzo wyraźny. Właśnie dlatego wybór usługi warto oprzeć nie na logo dostawcy, tylko na konkretnych wymaganiach.
Jak wybrać usługę dla strony, sklepu lub aplikacji
Przy wyborze nie zaczynam od marketingu, tylko od listy funkcji, które realnie zmieniają codzienną pracę. Dla bloga liczy się prostota, dla sklepu internetowego szybkie czyszczenie cache po aktualizacji cen, a dla aplikacji SaaS obsługa API, logów i kontroli ruchu na brzegu.
| Kryterium | Na co patrzeć | Dlaczego to ważne |
|---|---|---|
| Reguły cache | Czy da się precyzyjnie ustawić TTL, wyjątki i warunki przechowywania | Bez tego łatwo przyspieszyć złą treść albo zapchać cache |
| Purge i invalidation | Jak szybko można wyczyścić konkretne pliki po wdrożeniu | To kluczowe przy zmianach cen, grafik i wersji frontendu |
| Obsługa dynamicznego ruchu | Reguły dla API, nagłówków, cookies i sesji | Chroni przed buforowaniem danych, które nie powinny być współdzielone |
| Bezpieczeństwo | WAF, ochrona DDoS, rate limiting, TLS | CDN coraz częściej pełni też rolę pierwszej warstwy obrony |
| Logi i monitoring | Statystyki hit ratio, błędy, latencja, pochodzenie ruchu | Bez danych trudno ocenić, czy wdrożenie rzeczywiście działa |
| Model kosztowy | Transfer, liczba żądań, funkcje edge, opłaty za logi | Najtańszy plan na start nie zawsze jest najtańszy przy wzroście ruchu |
Jeśli miałbym wybrać jedną praktyczną zasadę, powiedziałbym tak: najpierw sprawdź, czy dostawca pozwala szybko i precyzyjnie zarządzać cache, a dopiero potem porównuj cenę. W sklepach i aplikacjach krytyczne są też mechanizmy wykluczania prywatnych odpowiedzi z cache oraz łatwe wycofanie zmian po deployu. Kiedy te elementy są dopięte, dopiero wtedy warto przejść do konfiguracji i unikać błędów, które zwykle wychodzą dopiero po wdrożeniu.
Najczęstsze błędy, które psują efekt
Największy problem nie polega na tym, że CDN działa źle, tylko na tym, że ktoś wkłada do niego niewłaściwe treści albo ustawia zbyt agresywne reguły. Efekt bywa wtedy dziwny: strona niby jest szybsza, ale pokazuje nieaktualne dane, koszyk zachowuje się niestabilnie albo po wdrożeniu część użytkowników widzi starą wersję layoutu.
- Cacheowanie treści spersonalizowanej - szczególnie niebezpieczne przy koszykach, panelach konta i odpowiedziach zależnych od sesji.
- Brak purge po publikacji zmian - jeśli nowa wersja pliku nie trafia od razu do wszystkich węzłów, użytkownicy widzą miks starych i nowych zasobów.
- Złe nagłówki HTTP - niepoprawny `Cache-Control`, `Vary` albo nadmiarowe `Set-Cookie` potrafią wyłączyć sensowny cache bez widocznego ostrzeżenia.
- Zakładanie, że CDN naprawi wolny backend - jeśli origin odpowiada po kilka sekund, warstwa edge tylko częściowo to maskuje.
- Ignorowanie cache key - zbyt szeroki albo zbyt wąski klucz sprawia, że zasób jest współdzielony tam, gdzie nie powinien, albo nigdy się nie trafia w cache.
- Brak pomiaru po wdrożeniu - bez porównania przed i po nie wiesz, czy inwestycja coś dała.
W praktyce najwięcej problemów robią nie same zasady, tylko wyjątki. To one decydują, czy CDN faktycznie przyspiesza stronę, czy tylko dokłada warstwę pośrednią do trudniejszego debugowania. A skoro każda dodatkowa warstwa wpływa również na bezpieczeństwo i rachunek, dobrze jest spojrzeć na nie razem.
Bezpieczeństwo i koszty, o których zwykle pamięta się za późno
W nowoczesnych wdrożeniach CDN bardzo często pełni rolę pierwszej linii obrony. Można na nim odsiać część ruchu botów, ograniczyć liczbę zapytań z jednego źródła, wymusić TLS, a nawet zatrzymać część ataków DDoS zanim dotrą do originu. To nie jest pełny system bezpieczeństwa, ale w praktyce potrafi znacząco zmniejszyć powierzchnię ataku.
Jednocześnie trzeba pamiętać, że warstwa edge nie zwalnia z ostrożności. Jeśli origin jest publicznie dostępny bez zabezpieczeń, jeśli reguły cache są zbyt luźne albo jeśli ktoś źle ustawi nagłówki, ryzyko nadal zostaje. CDN pomaga, ale nie zastępuje porządnej konfiguracji aplikacji, WAF-u i kontroli dostępu.
Po stronie kosztów największe znaczenie mają zwykle trzy rzeczy: transfer danych do użytkowników, liczba żądań oraz funkcje dodatkowe, takie jak edge compute, logowanie czy zaawansowana ochrona. Przy małym serwisie kwota bywa niewielka, ale przy kampaniach reklamowych, dużej liczbie obrazów albo ruchu wideo rachunek rośnie szybko. Z praktyki wiem też, że najwięcej kosztują nie same bajty, tylko nieprzemyślane wzorce dostępu, które generują masę małych requestów.
| Co podbija koszt | Dlaczego rośnie | Jak ograniczyć wydatek |
|---|---|---|
| Duży transfer do użytkowników | Każdy GB wychodzący do sieci ma znaczenie przy skali | Kompresja, lepsze formaty obrazów, cache statycznych plików |
| Wiele małych żądań | Ikony, skrypty i fragmenty frontendu mogą mnożyć requesty | Łączenie zasobów tam, gdzie ma to sens, oraz dłuższy TTL dla stabilnych plików |
| Częste unieważnianie cache | Każdy purge może wymuszać ponowne pobranie zasobów z originu | Lepsze wersjonowanie plików i bardziej precyzyjne reguły publikacji |
| Funkcje edge i bezpieczeństwo | Zaawansowane reguły, logi i filtracja nie zawsze są w podstawowym pakiecie | Włączać tylko to, co faktycznie rozwiązuje problem |
Właśnie przez ten podwójny wpływ - na obronę i na budżet - warto przygotować wdrożenie tak, jak przygotowuje się każdą zmianę infrastrukturalną, a nie jak zwykłe „przeklikanie ustawień”.
Co sprawdzić przed wdrożeniem na produkcji
Zanim włączę warstwę edge na żywej usłudze, przechodzę przez prostą checklistę. To oszczędza czas, bo większość problemów pojawia się w tych samych miejscach: błędne nagłówki, zbyt szeroki cache, brak strategii odświeżania i brak punktu odniesienia po stronie metryk.
- Ustal, które zasoby mają być cacheowane, a które muszą zawsze iść do originu.
- Sprawdź nagłówki `Cache-Control`, `Vary`, `ETag` i zachowanie przy `Set-Cookie`.
- Zaplanuj purge po każdym deployu, który zmienia front lub dane statyczne.
- Porównaj wyniki przed i po: TTFB, czas ładowania strony, cache hit ratio i liczbę requestów do originu.
- Przetestuj scenariusze awaryjne, czyli chwilowy brak originu, wzrost ruchu i ponowne wdrożenie wersji.
- Upewnij się, że panel administracyjny, koszyk i logowanie nie wpadają przypadkiem do cache publicznego.