
Łączenie lewostronne, czyli left join, przydaje się wtedy, gdy chcesz zachować wszystkie wiersze z jednej tabeli, nawet jeśli druga nie ma dopasowania. W praktyce to jedno z najważniejszych narzędzi w raportach, analizie braków i budowaniu widoków, które mają pokazać pełny obraz danych, a nie tylko ich wspólną część. Poniżej rozkładam ten mechanizm na prosty przykład, pokazuję różnicę między warunkami w ON i WHERE oraz podpowiadam, kiedy takie łączenie naprawdę ma sens.
Najważniejsze rzeczy, które warto wiedzieć o tym łączeniu
- Zachowuje wszystkie wiersze z lewej tabeli, a z prawej dokleja tylko pasujące rekordy.
- Gdy po prawej stronie nie ma dopasowania, wynik dostaje NULL zamiast pustego rekordu.
- ON decyduje o dopasowaniu, a WHERE filtruje już gotowy wynik, więc zły warunek potrafi zniszczyć efekt łączenia.
- Najlepiej sprawdza się w raportach, analizie brakujących danych i przy modelach 1 do wielu.
- Jeśli wynik wygląda dziwnie, pierwsze miejsce do sprawdzenia to kolejność tabel, warunki filtrowania i to, czy nie mnożysz wierszy przez zbyt szeroką relację.
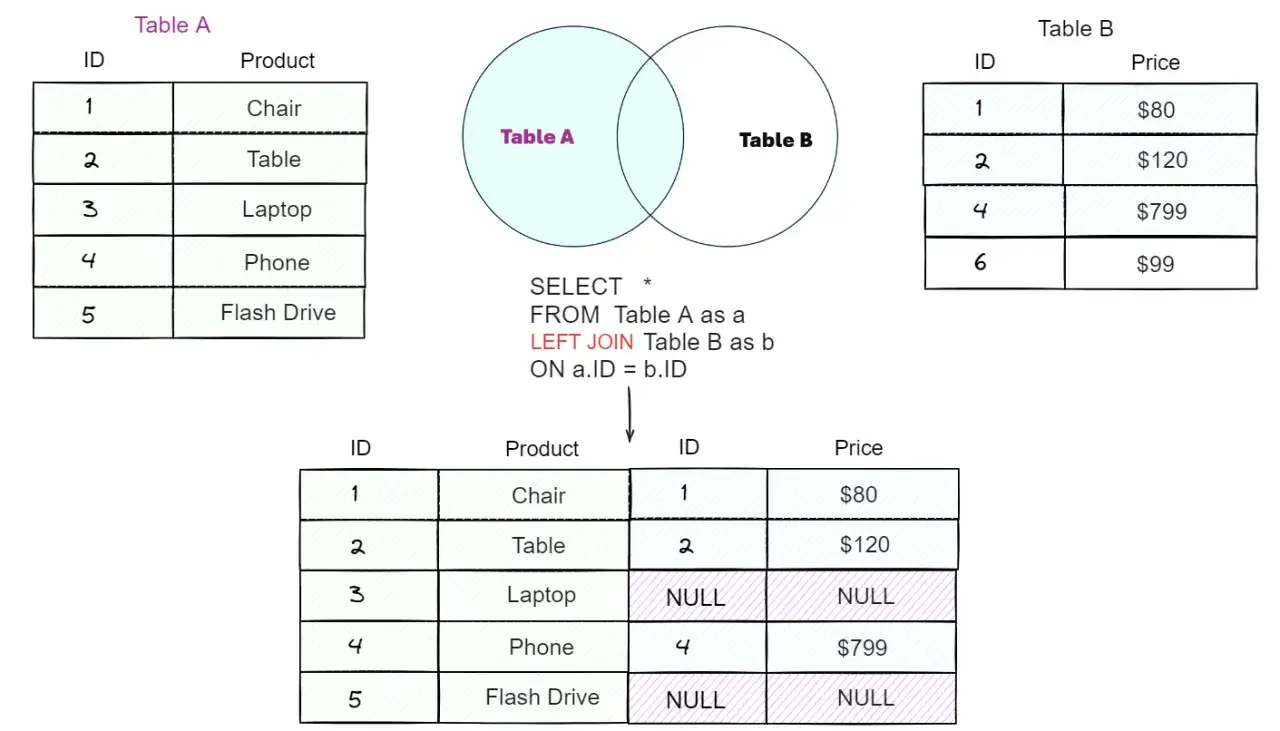
Jak działa łączenie lewostronne w praktyce
Myślę o nim jak o regule: „zostaw wszystko z lewej strony, a po prawej dołącz tylko to, co pasuje”. Silnik SQL bierze każdy wiersz z tabeli po lewej, szuka dopasowania po prawej i jeśli go nie znajdzie, nie usuwa rekordu, tylko uzupełnia brakujące kolumny wartościami NULL. To właśnie odróżnia ten mechanizm od zwykłego łączenia wewnętrznego, które pokazuje wyłącznie część wspólną obu tabel.
Ważny jest też sam warunek w ON. To on mówi, które rekordy mają zostać sparowane. Jeśli ten warunek jest zbyt szeroki albo zbyt wąski, wynik zmieni się od razu. Warto pamiętać, że NULL nie oznacza „0” ani „pустego tekstu” - to po prostu brak wartości, czyli sygnał, że po prawej stronie nie znaleziono dopasowania. Gdy raport ma pokazać luki, braki w relacjach albo klientów bez zamówień, taka informacja jest często cenniejsza niż sam komplet dopasowań.
Najprościej mówiąc: to łączenie nie „gubi” lewej tabeli. Ono pozwala zobaczyć ją w całości i jednocześnie sprawdzić, co udało się do niej dołączyć. Na tym tle łatwiej zrozumieć przykład, w którym wynik widać od razu.
Przykład na klientach i zamówieniach
Załóżmy, że mam tabelę customers z listą klientów oraz tabelę orders z zamówieniami. Chcę dostać wszystkich klientów, nawet tych, którzy jeszcze nic nie kupili. Właśnie tutaj zwykłe łączenie wewnętrzne byłoby zbyt restrykcyjne, bo wyrzuciłoby osoby bez przypisanego zamówienia.
SELECT c.id, c.name, o.id AS order_id, o.total
FROM customers c
LEFT OUTER JOIN orders o
ON o.customer_id = c.id;Wynik może wyglądać tak:
| id | name | order_id | total |
|---|---|---|---|
| 1 | Anna | 301 | 125.00 |
| 2 | Bartek | NULL | NULL |
| 3 | Celina | 302 | 89.90 |
To jest sedno całej operacji: Bartek nadal pojawia się w wyniku, mimo że nie ma dopasowanego rekordu w tabeli zamówień. W raportach sprzedaży, CRM albo analizie aktywności użytkowników taki brak bywa równie ważny jak samo zamówienie. Dzięki temu od razu widzę, kto jest aktywny, a kto wymaga dopiero kontaktu lub aktywacji. Gdy ten mechanizm jest już jasny, najczęstszy problem zaczyna się gdzie indziej - w filtrach.
Dlaczego warunek w where potrafi zepsuć wynik
To błąd, który widzę bardzo często: ktoś pisze poprawne łączenie, a potem dokłada filtr w WHERE i dziwi się, że zniknęły rekordy bez dopasowania. Dzieje się tak dlatego, że WHERE działa po łączeniu, więc usuwa także wiersze, w których po prawej stronie pojawiło się NULL.
Spójrz na ten wariant:
SELECT c.name, o.total
FROM customers c
LEFT OUTER JOIN orders o
ON o.customer_id = c.id
WHERE o.total > 100;Na pierwszy rzut oka wygląda dobrze, ale w praktyce filtr WHERE o.total > 100 odrzuci także klientów bez zamówień, bo dla nich o.total jest NULL. Jeśli naprawdę chcesz zachować klientów i jednocześnie ograniczyć dopasowane zamówienia, warunek powinien trafić do ON:
SELECT c.name, o.total
FROM customers c
LEFT OUTER JOIN orders o
ON o.customer_id = c.id
AND o.total > 100;Ta różnica bywa subtelna, ale robi ogromną zmianę w wynikach. Ja zwykle stosuję prostą zasadę: warunki, które mają decydować o dopasowaniu rekordów, trzymam w ON, a warunki, które mają filtrować już gotowy wynik, zostawiam w WHERE. Jeśli chcę znaleźć wyłącznie rekordy bez dopasowania, sprawdzam po stronie prawej kolumnę, która nie powinna być pusta, na przykład klucz główny, i filtruję ją przez IS NULL. To prowadzi naturalnie do pytania, kiedy to łączenie warto wybrać zamiast innych.
Czym różni się od inner, right i full join
Gdy pracuję nad zapytaniem, lubię porównać kilka typów łączeń obok siebie. Wtedy od razu widać, czy naprawdę potrzebuję pełnego obrazu danych, czy wystarczy wspólna część. Najlepiej pokazuje to proste zestawienie.
| Rodzaj łączenia | Co zwraca | Kiedy użyć | Na co uważać |
|---|---|---|---|
| Inner join | Tylko wiersze dopasowane po obu stronach | Gdy interesuje Cię wyłącznie część wspólna danych | Ukrywa rekordy bez pary, więc nie pokaże braków |
| Łączenie lewostronne | Wszystkie wiersze z lewej tabeli i dopasowania z prawej | Gdy chcesz zachować komplet lewej strony, np. wszystkich klientów | Może zwracać NULL i mnożyć wiersze przy relacji 1 do wielu |
| Right outer join | Wszystkie wiersze z prawej tabeli i dopasowania z lewej | Gdy logicznie patrzysz z perspektywy prawej tabeli | W praktyce często wygodniej przepisać zapytanie na wersję lewostronną |
| Full outer join | Wszystkie wiersze z obu tabel, z NULL tam, gdzie brak dopasowania | Gdy porównujesz dwa zbiory i chcesz zobaczyć braki po obu stronach | Wynik bywa duży i trudniejszy do interpretacji |
W praktyce najczęściej sięgam po inner join albo wersję lewostronną, bo są czytelniejsze i zwykle wystarczają. Prawy wariant rzadko daje realną przewagę, a pełne łączenie ma sens dopiero wtedy, gdy rzeczywiście porównujesz dwa niezależne zbiory danych. Skoro różnice są już jasne, warto jeszcze spojrzeć na kwestie, które zaczynają boleć przy większych tabelach.
Na co uważać przy większych zbiorach danych
Największy błąd początkujących nie dotyczy składni, tylko modelu danych. Jeśli jeden wiersz z lewej strony ma kilka dopasowań po prawej, wynik naturalnie się powieli. To nie jest awaria SQL, tylko konsekwencja relacji 1 do wielu albo wielu do wielu. Jeśli potrzebujesz jednego wiersza na klienta, a po prawej masz wiele zamówień, zwykle trzeba najpierw zwinąć dane agregacją, a dopiero potem je łączyć.
Druga sprawa to wydajność. Indeksy na kolumnach łączenia mają znaczenie, szczególnie gdy tabele są duże, a warunek opiera się na często używanym kluczu. Pomaga też unikanie funkcji na kolumnach używanych do dopasowania, bo silnik ma wtedy mniejsze szanse na wykorzystanie indeksu. To nie znaczy, że każda optymalizacja będzie identycznie skuteczna w każdym systemie, ale zasada jest stabilna: im prostszy warunek i lepiej przygotowane dane, tym mniej pracy dla bazy.
Wreszcie, przy łączeniach zewnętrznych silnik ma trochę mniej swobody niż przy zwykłym łączeniu wewnętrznym. To ważne przy złożonych raportach, gdzie kilka tabel łączy się jedna po drugiej. Jeśli dane zaczynają się „rozjeżdżać”, ja najpierw sprawdzam typy kolumn, aliasy, kardynalność relacji i to, czy żadna z tabel nie wnosi niepotrzebnych duplikatów. Z tego miejsca już tylko krok do szybkiego sprawdzenia, czy zapytanie jest napisane rozsądnie.
Trzy szybkie sprawdzenia przed uruchomieniem raportu
- Czy warunki, które mają zachować brak dopasowania, trafiły do ON, a nie do WHERE?
- Czy po prawej stronie filtruję kolumnę, która faktycznie nie może być pusta, jeśli chcę wykryć brak rekordu?
- Czy jedno dopasowanie nie powiela mi się kilka razy przez relację 1 do wielu?
Jeśli te trzy rzeczy się zgadzają, większość problemów znika jeszcze zanim zaczniesz szukać błędów w danych źródłowych. W praktyce właśnie dlatego łączenie lewostronne jest tak użyteczne: pozwala jednocześnie zobaczyć komplet podstawowej tabeli i szybko wyłapać luki, które w zwykłym zestawieniu mogłyby pozostać niewidoczne.