Patrzę na ten temat przede wszystkim praktycznie: model neuronowy jest wartościowy wtedy, gdy potrafi wyłapywać wzorce z danych, których nie da się sensownie opisać prostymi regułami. Najprościej mówiąc, sieć neuronowa uczy się z danych zamiast polegać na sztywnym zestawie instrukcji. W tym artykule pokazuję, jak działa od środka, kiedy naprawdę daje przewagę i jakie błędy najczęściej psują wyniki w praktyce.
Najważniejsze rzeczy, które warto wiedzieć przed pracą z modelami neuronowymi
- To model uczący się wzorców z danych, a nie zestaw ręcznie zapisanych reguł.
- Najmocniej sprawdza się przy obrazach, tekście, mowie i innych danych nieustrukturyzowanych.
- Jakość danych i etykiet zwykle ma większy wpływ niż sama złożoność architektury.
- Przy małych, tabelarycznych zbiorach prostsze modele często wygrywają szybkością i stabilnością.
- Wdrożenie nie kończy się na treningu: potrzebne są walidacja, monitoring i kontrola kosztów.
Jak działa model neuronowy od wejścia do wyniku
Żeby dobrze zrozumieć taki model, trzeba zobaczyć trzy rzeczy: wejście, obliczenia w warstwach i korektę błędu. Ja patrzę na to jak na system, który z każdą iteracją poprawia własne ustawienia, aż zaczyna coraz lepiej odwzorowywać zależność między danymi wejściowymi a oczekiwanym wynikiem.
Dane muszą zostać zapisane jako liczby
Model nie "widzi" surowego zdjęcia czy zdania tak jak człowiek. Najpierw zamieniasz dane na liczby: piksele, tokeny, wektory cech albo embeddingi, czyli gęste reprezentacje znaczenia. To ważne, bo jakość tego kroku często decyduje o całym projekcie.
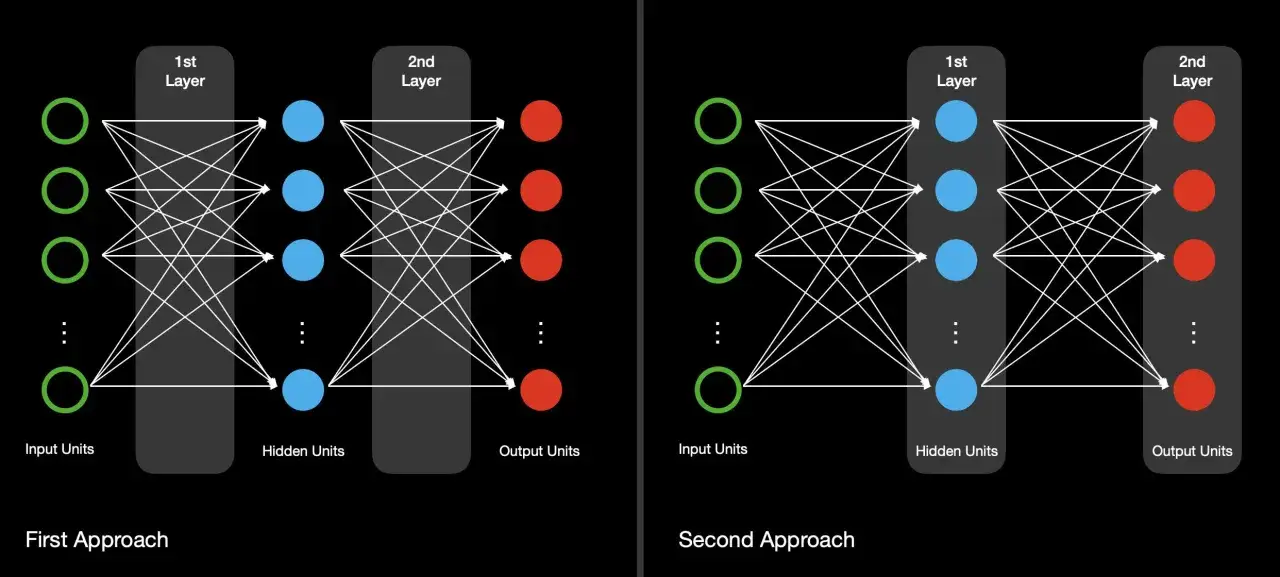
Warstwy liczą wynik krok po kroku
Każdy neuron bierze wejścia, nadaje im wagi, dodaje bias i przepuszcza wynik przez funkcję aktywacji. W praktyce oznacza to, że sieć buduje coraz bardziej złożony obraz danych: pierwsze warstwy widzą proste wzorce, kolejne łączą je w bardziej abstrakcyjne relacje. Dzięki temu model potrafi rozpoznać na przykład krawędzie na obrazie, a później całe obiekty albo intencję w zdaniu.
Przeczytaj również: Jak zrobić reset komputera Windows 10 i uniknąć utraty danych
Trening poprawia wagi, a inferencja tylko korzysta z nauki
Podczas treningu model porównuje swoją odpowiedź z prawidłowym wynikiem, liczy błąd loss i koryguje parametry metodą gradient descent, a dokładniej przez backpropagation. To właśnie tu dzieje się właściwe uczenie. Inferencja jest prostsza: model używa już wyuczonych wag, żeby przygotować prognozę dla nowych danych, bez dalszej zmiany parametrów.
Gdy ten mechanizm jest jasny, łatwiej odróżnić architekturę dobrą do obrazów od tej, która lepiej radzi sobie z sekwencjami.
Jakie typy spotyka się najczęściej
Różne architektury powstały po to, by lepiej radzić sobie z innym rodzajem danych. Wybór nie powinien wynikać z mody, tylko z tego, czy problem jest przestrzenny, sekwencyjny, czy raczej prosty i tabelaryczny.
| Typ | Najlepsze zastosowanie | Mocna strona | Ograniczenie |
|---|---|---|---|
| Feedforward | Klasyfikacja, scoring, prostsze predykcje | Prosty i szybki start | Słabiej radzi sobie z obrazami i sekwencjami |
| CNN | Obrazy, wideo, OCR | Świetnie wyłapuje lokalne wzorce | Wymaga danych o strukturze przestrzennej |
| RNN | Szeregi czasowe, starsze systemy tekstowe | Uwzględnia kolejność elementów | Trudniej trenować, dziś często ustępuje nowszym architekturom |
| Transformer | Tekst, kod, chatboty, zadania multimodalne | Dobrze analizuje zależności w sekwencji dzięki mechanizmowi uwagi | Bywa kosztowny i wymaga sensownej skali danych oraz mocy obliczeniowej |
To właśnie transformery stoją dziś za wieloma systemami językowymi i generatywnymi, ale nie oznacza to, że starsze podejścia straciły sens. Jeśli ktoś pyta mnie, co wybrać na start, odpowiadam krótko: najpierw dopasuj architekturę do typu danych, dopiero potem myśl o rozmiarze modelu.
Gdzie sprawdza się najlepiej, a gdzie przegrywa z prostszymi metodami
Największą przewagę takie modele mają wtedy, gdy dane są nieustrukturyzowane albo zależności są zbyt złożone, by opisać je prostymi regułami. W polskich firmach najczęściej widać to w analizie dokumentów, rozpoznawaniu mowy, klasyfikacji zgłoszeń, wyszukiwaniu produktów i rekomendacjach.
- Tekst, obraz, audio, wideo, logi i sygnały czasowe to naturalne środowisko dla modeli neuronowych.
- Sprawdzają się tam, gdzie trzeba wykrywać podobieństwo semantyczne, wzorce i zależności długiego zasięgu.
- Przy małych, tabelarycznych zbiorach danych często lepsze są drzewa gradient boosting albo regresja logistyczna.
- Jeśli potrzebna jest pełna interpretowalność, model neuronowy może być trudniejszy do obrony przed biznesem lub audytem.
- Jeżeli dane są słabe jakościowo, sama architektura nie naprawi problemu.
Ja zwykle zaczynam od prostego baseline'u: regresji logistycznej, drzewa albo XGBoost. Jeśli taki model daje wynik zbliżony do sieci neuronowych, a jest tańszy i łatwiejszy do wyjaśnienia, nie ma sensu komplikować projektu tylko dlatego, że deep learning brzmi nowocześnie. To jedna z tych decyzji, które oszczędzają miesiące pracy.
Kiedy już wiesz, że problem naprawdę wymaga takiego podejścia, trzeba przejść do wdrożenia, bo tam najczęściej pojawia się koszt i większość rozczarowań.
Jak wygląda sensowne wdrożenie w firmie
Dobre wdrożenie nie zaczyna się od modelu, tylko od danych i metryki. W praktyce patrzę na proces w czterech krokach, bo dopiero ich spójność daje wynik, który da się utrzymać po wyjściu poza notebook.
| Etap | Co sprawdzam | Typowy błąd |
|---|---|---|
| Dane | Czyszczenie, etykietowanie, balans klas | Duplikaty, braki i pośpieszne etykiety |
| Podział | Train, validation i test, zwykle 70/15/15 albo 80/10/10 | Przeciek danych, czyli uczenie się z informacji, których model nie powinien znać |
| Trening | Baseline, transfer learning, fine-tuning | Budowanie wszystkiego od zera, choć nie ma takiej potrzeby |
| Ocena i wdrożenie | F1, ROC-AUC, MAE, latency i drift | Patrzenie wyłącznie na accuracy |
Przy większych projektach kluczowe jest też to, że trening od zera bywa kosztowny obliczeniowo. W wielu przypadkach lepiej działa gotowy model wstępnie wytrenowany i dopasowany do własnych danych niż budowanie wszystkiego od podstaw. To szczególnie ważne wtedy, gdy zespół nie ma dużej puli GPU albo potrzebuje szybkiego zwrotu z projektu.
Nawet dobrze ustawiony projekt może jednak polec, jeśli po drodze popełni się kilka klasycznych błędów.
Najczęstsze błędy, które psują wyniki
Największy problem rzadko leży w samej architekturze. Ja najbardziej obawiam się błędów w danych, bo one potrafią zniszczyć nawet bardzo dobrą koncepcję.
- Za mało danych albo zbyt mało różnorodne przykłady sprawiają, że model uczy się pamięci, a nie wzorca.
- Słabe etykiety są równie groźne jak ich brak, bo model uczy się błędu z pełną konsekwencją.
- Data leakage, czyli przeciek informacji z testu do treningu, daje sztucznie piękny wynik.
- Zbyt duży model do małego problemu oznacza więcej parametrów, ale niekoniecznie więcej wartości biznesowej.
- Patrzenie na jedną metrykę potrafi wprowadzić w błąd, zwłaszcza przy nierównych klasach.
- Brak regularizacji kończy się overfittingiem, czyli dopasowaniem do szumu zamiast do prawdziwego wzorca.
W praktyce pomagają proste zabezpieczenia: sensowna walidacja, early stopping, dropout, kontrola jakości etykiet i testowanie modelu na danych, które naprawdę przypominają środowisko produkcyjne. Kiedy te pułapki są pod kontrolą, można już myśleć o prostym planie startowym zamiast o teoretycznie idealnym, ale martwym modelu.
Co warto sprawdzić przed wdrożeniem
Zanim uruchomię taki projekt, zadaję sobie trzy pytania: czy problem naprawdę ma charakter wzorcowy, czy mam dane w wystarczającej jakości i czy potrafię mierzyć sukces w sposób zgodny z biznesem. Jeżeli na któreś z nich odpowiadam niepewnie, zaczynam od prostszego rozwiązania i dopiero potem porównuję je z modelem neuronowym.
- Czy mam co najmniej sensowny zbiór danych i jasne etykiety?
- Czy lepsza byłaby klasyczna metoda, bo problem jest mały, tabelaryczny albo wymaga wyjaśnialności?
- Czy mam plan monitoringu po wdrożeniu, żeby wykryć drift danych i spadek jakości?
- Czy koszty obliczeń i utrzymania są proporcjonalne do zysku?
Jeśli te warunki są spełnione, model neuronowy staje się bardzo mocnym narzędziem. Jeśli nie, rozsądniej jest zacząć prościej, bo w AI najdrożej kosztuje nie sama technologia, tylko błędne założenie, że każda задача wymaga najcięższej architektury.