Narzędzie śledzące trasę pakietów pozwala szybko ustalić, gdzie ginie połączenie, skąd biorą się opóźnienia i czy problem leży w sieci lokalnej, u operatora, czy po stronie celu. W praktyce to jedno z najbardziej użytecznych narzędzi diagnostycznych, ale tylko wtedy, gdy rozumie się, co naprawdę pokazuje, a czego nie pokazuje. Poniżej rozkładam to na proste zasady, typowe wyniki i najczęstsze pułapki.
Najkrócej: to narzędzie pokazuje kolejne przystanki pakietu i pomaga wskazać, gdzie zaczyna się problem
- Pokazuje po kolei routery, przez które przechodzi pakiet, czyli tak zwane hop-y.
- Domyślnie wiele implementacji ogranicza trasę do 30 skoków, więc wynik nie zawsze obejmie całą drogę.
- Windowsowy `tracert` i uniksowe odmiany mogą wysyłać inne typy sond, dlatego wynik bywa podobny, ale nie identyczny.
- Gwiazdki `* * *` nie muszą oznaczać awarii, często są skutkiem filtrowania lub limitowania odpowiedzi.
- Najlepsze efekty daje porównanie wyniku z `ping`, a przy dłuższych problemach także z `mtr`.
Jak działa traceroute w praktyce
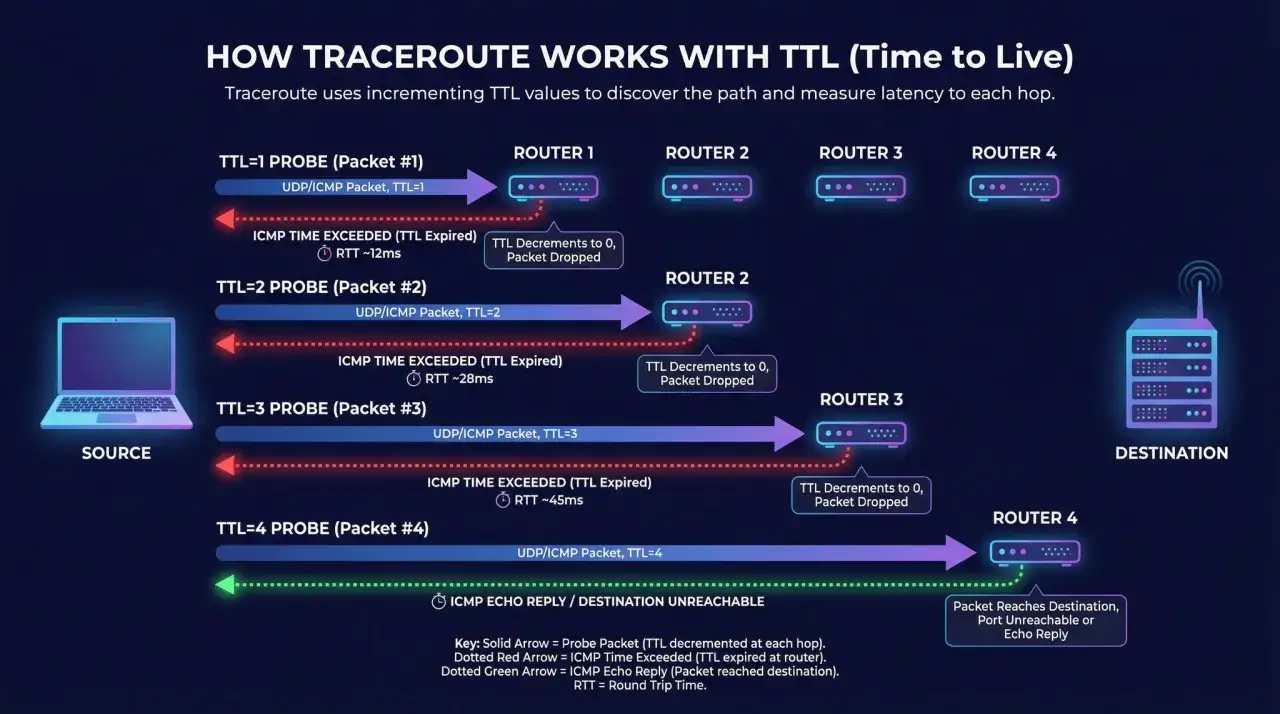
Mechanizm jest prosty, ale bardzo sprytny. Pakiet dostaje wartość TTL czyli licznik życia, który jest zmniejszany o jeden na każdym routerze po drodze. Gdy TTL spadnie do zera, router odrzuca pakiet i odsyła komunikat o przekroczeniu czasu życia, a właśnie z tych odpowiedzi buduje się lista kolejnych przystanków.
W praktyce narzędzie zaczyna od TTL ustawionego na 1, potem 2, 3 i tak dalej, aż dotrze do celu albo do limitu skoków. TTL jest polem 8-bitowym, więc teoretycznie może przyjąć wartości do 255, ale w codziennej diagnostyce najczęściej spotkasz limit 30 skoków. To wystarcza w większości sieci, choć w bardziej złożonych trasach może nie pokazać całej drogi.
Najważniejsze jest dla mnie to, że ten test pokazuje trasę w jednym kierunku. To oznacza, że widzisz drogę pakietu do celu, ale niekoniecznie identyczną drogę odpowiedzi z powrotem. W sieciach z wieloma wyjściami, VPN-em albo load balancingiem ten szczegół ma ogromne znaczenie. Jeśli wynik wydaje się dziwny, często nie ma w nim błędu narzędzia, tylko po prostu logika routingu jest bardziej złożona niż oczekujesz.
Na końcu tej układanki zostaje jedno praktyczne pytanie: jak odróżnić normalny wynik od rzeczywistej awarii, więc właśnie na tym skupię się teraz.
Jak czytać wynik bez zgadywania
Wynik najłatwiej rozbić na trzy rzeczy: numer skoku, czasy odpowiedzi i nazwę lub adres urządzenia. Numer skoku mówi, na którym etapie jest pakiet, czasy pokazują opóźnienie, a nazwa hosta lub adres IP pomagają ustalić, gdzie dokładnie leży dany element trasy.
| Element wyniku | Co oznacza | Jak to interpretuję |
|---|---|---|
| Numer skoku | Kolejny router lub urządzenie pośrednie | Im wyższy numer, tym dalej od źródła znajduje się odpowiedź |
| Czasy w ms | Oszacowanie opóźnienia dla danej próby | Stabilne wartości zwykle oznaczają zdrową ścieżkę, a duże wahania wskazują na przeciążenie lub kolejkę |
| Nazwa hosta / IP | Urządzenie lub interfejs, który odpowiedział | Nazwa bywa wygodna, ale IP jest bardziej jednoznaczne |
| `* * *` | Brak odpowiedzi w czasie oczekiwania | Nie zakładam od razu awarii, bo przyczyną może być filtr, limit odpowiedzi albo priorytetyzacja ruchu |
| Adres celu | Ostatni hop, czyli host docelowy | Jeśli test kończy się na celu, trasa została wyznaczona poprawnie |
Na początku trasy często pojawiają się prywatne adresy z zakresów typu 192.168.x.x lub 10.x.x.x. To normalne, bo pakiet najpierw przechodzi przez router domowy, firmowy firewall albo brzegową bramę operatora. Dopiero później wychodzi do publicznej części sieci.
Jeśli wyniki są długie albo trudno je porównać między kolejnymi próbami, warto wiedzieć, że nazwy hostów potrafią spowalniać odczyt przez dodatkowe zapytania DNS. To prowadzi do różnic między systemami, które dobrze znać przed wyciąganiem wniosków.
Dlaczego Windows, Linux i router Cisco pokazują coś innego
Tu zaczyna się najczęstsze źródło nieporozumień. Sam pomysł działania jest ten sam, ale szczegóły implementacji różnią się między systemami, więc identyczny test może dać trochę inny wygląd wyniku. To nie znaczy, że jedna wersja jest lepsza, tylko że każda wysyła sondy w nieco inny sposób.
| Środowisko | Typ sondy | Praktyczny skutek |
|---|---|---|
| Windows `tracert` | ICMP echo request | Bywa skuteczniejszy tam, gdzie UDP jest filtrowane, ale odpowiedzi nadal mogą być ograniczane przez polityki sieciowe |
| Linux i wiele odmian uniksowych | Najczęściej UDP, czasem ICMP lub TCP zależnie od wariantu | Wynik może wyglądać inaczej, zwłaszcza gdy sieć inaczej traktuje konkretne protokoły |
| Cisco IOS | Typowo UDP z rosnącym TTL | Przydatne w diagnostyce routerów, ale też podatne na filtrację i limitowanie odpowiedzi |
W praktyce sprowadza się to do jednego: jeśli porównujesz wyniki z różnych systemów, porównuj trend, a nie sam format. Najważniejsze pytanie brzmi nie „czy wyglądają identycznie”, tylko „od którego skoku zaczyna się problem i czy powtarza się konsekwentnie”.
To naturalnie prowadzi do wyboru narzędzia. Czasem wystarczy prosty test dostępności, a czasem potrzebujesz właśnie analizy kolejnych hopów lub dłuższego monitorowania zmian w trasie.
Kiedy użyć tego narzędzia, a kiedy wystarczy ping lub mtr
W diagnostyce sieci nie chodzi o to, żeby odpalić najdłuższy możliwy test, tylko o to, żeby dobrać właściwe narzędzie do pytania. Gdy chcę tylko sprawdzić, czy host odpowiada, używam `ping`. Gdy muszę znaleźć miejsce, w którym połączenie zwalnia albo znika, potrzebuję narzędzia pokazującego trasę. A gdy problem jest niestabilny, wolę obserwację w czasie, czyli `mtr`.
| Narzędzie | Co pokazuje | Kiedy jest najlepsze | Ograniczenie |
|---|---|---|---|
| `ping` | Dostępność celu i czas odpowiedzi | Gdy chcesz szybko sprawdzić, czy host żyje | Nie pokazuje drogi pakietu |
| Śledzenie trasy pakietów | Kolejne przystanki po drodze | Gdy szukasz miejsca awarii lub opóźnienia | Nie zawsze ujawnia wszystkie routery i nie opisuje trasy powrotnej |
| `mtr` | Trasę oraz statystyki pakietów w czasie | Gdy problem jest losowy, zmienny albo pojawia się okresowo | Wymaga dłuższego zbierania danych, więc nie zawsze nadaje się do szybkiego strzału |
| `pathping` | Połączenie testu trasy i strat w czasie | Gdy pracujesz na Windows i chcesz dłuższej analizy strat | Jest wolniejszy od prostego testu |
Gdybym miał ująć to jednym zdaniem, powiedziałbym tak: ping odpowiada na pytanie „czy działa”, a analiza trasy odpowiada na pytanie „gdzie przestaje działać”. `mtr` dorzuca do tego jeszcze perspektywę czasu, więc świetnie łapie problemy przejściowe.
Wybór narzędzia to dopiero połowa sukcesu. Druga połowa to zrozumienie, kiedy wynik jest wiarygodny, a kiedy sieć po prostu nie chce odpowiedzieć w prosty sposób.
Najczęstsze pułapki w diagnostyce tras
Najbardziej zdradliwe są sytuacje, w których wynik wygląda na awarię, ale wcale nią nie jest. W sieciach spotykam kilka powtarzalnych mechanizmów, które potrafią zmylić nawet doświadczonego administratora.
- Asymetryczne routowanie - pakiet idzie jedną drogą, a odpowiedź wraca inną. To normalne w wielu sieciach, więc analiza pokazuje tylko fragment rzeczywistości.
- ECMP - równoważenie ruchu po ścieżkach o podobnym koszcie. W praktyce oznacza to, że kolejne próby mogą pokazać inną kolejność lub inny zestaw hopów.
- Rate limiting odpowiedzi - router ogranicza liczbę komunikatów typu Time Exceeded, żeby chronić własny proces sterujący. Gwiazdki wtedy nie oznaczają utraty danych użytkownika.
- CoPP i QoS - polityki ochrony i priorytetyzacji ruchu mogą obniżyć widoczność odpowiedzi diagnostycznych, bo urządzenie woli obsłużyć ważniejszy ruch niż sondy testowe.
- VPN, NAT i chmura - adresy i trasy zmieniają się po drodze, więc wynik może pokazywać inny obraz niż ten, który widzisz w swojej aplikacji.
Właśnie dlatego nie lubię wyciągać wniosków z jednego uruchomienia. Jeśli pierwszy albo drugi hop nie odpowiada, ale kolejne już tak, zwykle patrzę najpierw na filtrowanie odpowiedzi, a dopiero później na faktyczną awarię. Jeśli natomiast opóźnienia rosną od konkretnego miejsca i utrzymują się do końca, wtedy szukam realnego wąskiego gardła.
Po tej stronie diagnostyki najważniejsze staje się pytanie, jak ustawić test, żeby wynik był możliwie czytelny i porównywalny z innymi próbami.
Jak wycisnąć z testu więcej informacji
Największą różnicę robią drobne ustawienia. Nie trzeba od razu grzebać w zaawansowanych opcjach, ale warto zadbać o kilka rzeczy, bo one zmieniają jakość odczytu bardziej niż mogłoby się wydawać.
- Wyłącz rozwiązywanie nazw, gdy chcesz szybko porównać wyniki - na Windows służy do tego `-d`, a w wielu uniksowych wariantach odpowiednikiem jest `-n`. Dzięki temu widzisz adresy IP bez czekania na DNS.
- Podnoś limit skoków tylko wtedy, gdy to ma sens - domyślne 30 hopów wystarcza w większości przypadków, ale przy bardziej rozbudowanej sieci można potrzebować większego zakresu.
- Porównuj kilka uruchomień - pojedynczy wynik bywa mylący, a trzy pomiary z różnych godzin dają znacznie lepszy obraz.
- Zapisuj pierwszy problematyczny hop - to zwykle najcenniejsza informacja dla administratora albo operatora.
- Testuj z różnych miejsc - z sieci domowej, z firmowego VPN-u, z łącza komórkowego. Jeśli problem znika po zmianie punktu startowego, winny jest raczej konkretny segment trasy niż sam serwer docelowy.
Na Windows przydatny bywa też parametr czasu oczekiwania na odpowiedź, bo przy wolniejszych lub mocniej filtrowanych sieciach zbyt krótki timeout daje fałszywe gwiazdki. W praktyce nie chodzi o „ustaw najdłużej jak się da”, tylko o to, żeby okno pomiarowe pasowało do realiów danej sieci.
Gdy mam już wynik z kilku prób, zwykle nie patrzę dalej na samą listę hopów, tylko na to, co z niej faktycznie wynika dla użytkownika, operatora albo zespołu aplikacyjnego.
Co robię z takim wynikiem, zanim otworzę ticket do operatora
Najpierw sprawdzam, czy problem zaczyna się lokalnie. Jeśli pierwszy hop już ma duże opóźnienie albo nie odpowiada, zaczynam od własnego routera, Wi-Fi, kabla, DNS i konfiguracji bramy. Jeśli pierwsze hop-y są stabilne, a kłopot pojawia się dopiero dalej, wtedy mam mocniejszy argument, że sprawa dotyczy trasy poza moją siecią.
Potem porównuję wynik z innym typem testu. Jeżeli `ping` do celu działa, ale trasa pokazuje liczne gwiazdki, traktuję to ostrożnie i nie mówię jeszcze o awarii. Jeśli z kolei zarówno dostępność, jak i kolejne skoki zaczynają się psuć w tym samym miejscu, mam już solidny trop. W takich sytuacjach najbardziej pomaga krótki, konkretny raport: godzina testu, adres celu, pierwszy problematyczny hop, źródłowy adres IP i informacja, czy wynik powtarza się na kilku łączach.
To właśnie daje realną wartość: nie sama lista routerów, tylko odpowiedź na pytanie, gdzie kończy się Twoja sieć, a zaczyna cudzy problem. Najbardziej użyteczne jest zestawienie kilku pomiarów z różnych godzin i z różnych łączy, bo wtedy widać, czy masz do czynienia z chwilowym przeciążeniem, filtrowaniem odpowiedzi, czy trwałym błędem w trasie.