Błąd 500, czyli 500 internal server error, to sygnał, że serwer napotkał problem, którego nie umiał obsłużyć. W tym artykule pokazuję, co ten komunikat naprawdę oznacza, kiedy winna jest domena, a kiedy hosting, CDN albo aplikacja, oraz jak przejść od objawu do przyczyny bez zgadywania. To ważne szczególnie wtedy, gdy strona obsługuje ruch, sprzedaż lub logowanie, bo każda minuta przestoju ma realny koszt.
Najważniejsze fakty, zanim zaczniesz diagnozować problem
- Kod 500 oznacza awarię po stronie serwera, a nie problem z przeglądarką użytkownika.
- Domena, DNS i hosting to różne warstwy, więc nie każdy komunikat o błędzie oznacza awarię domeny.
- Najpierw sprawdzam logi, ostatnie wdrożenia, wtyczki, bazę danych i limity zasobów.
- Jeśli strona działa przez CDN albo reverse proxy, źródłem problemu może być backend, a nie sama domena.
- Uporczywe błędy 5xx mogą ograniczać crawlowanie i osłabiać widoczność w wyszukiwarce.
Co naprawdę oznacza kod 500
Najprościej mówiąc, ten kod informuje, że serwer dostał żądanie, ale nie był w stanie go poprawnie obsłużyć. MDN opisuje go jako ogólny komunikat na wypadek sytuacji, której serwer nie potrafi jednoznacznie sklasyfikować w bardziej szczegółowym kodzie 5xx. W praktyce oznacza to zwykle problem w aplikacji, konfiguracji, zasobach lub połączeniu z usługą zależną, na przykład bazą danych.
To ważne rozróżnienie, bo sam komunikat nie mówi jeszcze, co dokładnie się zepsuło. Dla właściciela strony taki błąd jest raczej początkiem diagnozy niż jej końcem. Ja zawsze traktuję go jak sygnał: żądanie dotarło do backendu, ale backend się wykoleił. Z tego powodu nie zaczynam od domysłów o przeglądarce użytkownika, tylko od warstw, które rzeczywiście mogły zawieść.
Jeżeli ten sam komunikat pojawia się tylko na jednej podstronie, przy formularzu albo po zalogowaniu, trop jest zwykle w kodzie aplikacji. Jeśli wysypuje się cała witryna, podejrzenie pada raczej na konfigurację serwera, zasoby hostingu albo integrację z pośrednikiem, takim jak CDN. To prowadzi wprost do najczęstszego błędu interpretacyjnego: mylenia problemu serwera z problemem domeny.
Domena, DNS i hosting nie oznaczają tego samego
W praktyce wiele osób mówi „domena padła”, kiedy w rzeczywistości problem siedzi zupełnie gdzie indziej. Domena to nazwa i adres, DNS tłumaczy ją na właściwy serwer, a hosting dostarcza miejsce, na którym działa aplikacja. Jeśli pojawia się błąd 500, to zwykle znaczy, że DNS już zadziałał, a strona dotarła do serwera, który nie umiał odpowiedzieć poprawnie.
| Warstwa | Za co odpowiada | Co zwykle dzieje się przy awarii | Czy zobaczysz 500 |
|---|---|---|---|
| Domena | Jest nazwą strony, którą wpisuje użytkownik | Przekierowanie nie działa, domena wygasła, trafiłeś na parking | Zwykle nie |
| DNS | Wskazuje, na jaki serwer ma trafić ruch | Przeglądarka nie potrafi odnaleźć hosta albo trafia w złe miejsce | Raczej nie |
| Hosting i aplikacja | Obsługują żądania i generują stronę | Wyjątek w kodzie, brak pamięci, błąd bazy danych, zła konfiguracja | Tak, bardzo często |
| CDN lub proxy | Pośredniczą między użytkownikiem a serwerem | Problem po stronie origin, reguł cache, WAF lub połączenia upstream | Tak, czasem z własnym brandingiem |
To rozróżnienie oszczędza sporo czasu. Gdy ktoś zaczyna od panelu rejestratora domeny, a problem leży w PHP albo bazie danych, naprawa tylko się opóźnia. Dlatego w diagnostyce rozdzielam te warstwy od razu, zamiast szukać winnego „w domenie” na ślepo.
Jak szybko zawęzić źródło awarii
Jeżeli błąd pojawił się nagle, najlepsza jest chłodna, krótka sekwencja testów. Ja zaczynam od prostych pytań: czy problem dotyczy całej witryny, czy tylko jednej ścieżki, czy występuje wszędzie, czy tylko u części użytkowników. To pozwala odróżnić awarię globalną od lokalnego konfliktu w aplikacji.
- Sprawdź zakres błędu. Jeśli 500 występuje tylko na jednym URL-u, podejrzewam konkretny moduł, wtyczkę, endpoint API albo fragment kodu.
- Otwórz stronę w trybie prywatnym i na innym łączu. To pomaga odsiać cache przeglądarki, lokalne rozszerzenia i dziwne efekty po stronie sieci użytkownika.
- Porównaj czas awarii z ostatnimi zmianami. W praktyce najczęściej winny jest deploy, aktualizacja wtyczki, zmiana reguł serwera albo nowa integracja.
- Sprawdź logi z tej samej minuty. To najszybsza droga do konkretu, bo log zwykle pokazuje wyjątek, brak połączenia z bazą albo błąd uprawnień.
- Jeśli używasz CDN lub proxy, testuj origin bez pośrednika. Czasem komunikat wygląda jak problem strony, a faktycznie wykrzacza się warstwa pośrednia.
Ta krótka triage zwykle wystarcza, żeby odsiać przypadkowe tropy. Kiedy już widzę, że problem naprawdę siedzi po stronie serwera, przechodzę do najczęstszych przyczyn technicznych.
Najczęstsze przyczyny po stronie serwera
Według MDN do najczęstszych źródeł należą błędna konfiguracja serwera, problemy z pamięcią, nieobsłużone wyjątki i uprawnienia plików. W realnych wdrożeniach lista wygląda trochę szerzej, ale właśnie te punkty wracają najczęściej, niezależnie od tego, czy chodzi o WordPress, sklep internetowy, panel klienta czy API.
| Objaw | Najbardziej prawdopodobna przyczyna | Co sprawdzić pierwsze |
|---|---|---|
| Strona pokazuje białą stronę albo 500 po logowaniu | Fatal error w PHP, konflikt wtyczki, motywu lub brak pamięci | Logi aplikacji, wersję PHP, wyłączenie ostatnio dodanych rozszerzeń |
| Błąd pojawił się po aktualizacji | Niekompatybilna wersja komponentu albo zła konfiguracja wdrożenia | Rollback, changelog, test na stagingu, porównanie konfiguracji |
| Problem występuje przy większym ruchu | Wyzerowane zasoby, limit procesów, przeciążenie bazy danych | CPU, RAM, I/O, limity workerów, cache, indeksy bazy |
| Błąd dotyczy tylko formularza, płatności lub API | Timeout, wyjątek w integracji z usługą zewnętrzną, niepoprawna walidacja danych | Logi endpointu, timeouty, odpowiedzi zewnętrznego serwisu, mapowanie błędów |
| Awaria zaczęła się po migracji | Uprawnienia plików, brak rozszerzenia, błędne zmienne środowiskowe, zła ścieżka do bazy | Permissions, konfigurację środowiska, dostęp do DB, wymagane moduły |
Jeśli mam wskazać jeden błąd, który początkujący najczęściej bagatelizują, to jest nim brak logowania i brak porównania z ostatnią zmianą. Bez tego naprawa zamienia się w zgadywanie. Dlatego przy własnej stronie od razu przechodzę do checklisty operacyjnej.
Co sprawdzić krok po kroku, gdy zarządzasz stroną
Tu nie chodzi o rozbudowaną teorię, tylko o kolejność działań. W praktyce najwięcej czasu oszczędza mi podejście warstwowe: aplikacja, baza danych, serwer, integracje. Każdy z tych poziomów potrafi wywołać ten sam komunikat, ale wymaga innej naprawy.
Aplikacja i wtyczki
Jeśli strona działa na CMS-ie, zaczynam od ostatnich zmian: nowych wtyczek, motywu, modułów e-commerce, cache albo reguł bezpieczeństwa. W WordPressie i podobnych systemach konflikt dodatków jest jedną z najprostszych dróg do błędu 500. Tu pomaga szybkie wyłączenie ostatniego elementu, a jeśli to niemożliwe, porównanie z wersją sprzed wdrożenia.
Baza danych i konfiguracja
Drugi krok to połączenie z bazą i pliki konfiguracyjne. Zwracam uwagę na błędne dane dostępu, wygasłe hasła, nieprawidłową nazwę hosta bazy i brak wymaganych zmiennych środowiskowych. Przy migracjach często wychodzą też problemy z uprawnieniami do plików oraz z wersją PHP, która nie pasuje do kodu aplikacji.
Przeczytaj również: Jaką nazwę przyjmie las po utworzeniu w nim pierwszej domeny?
Serwer i zasoby
Jeżeli błąd pojawia się przy większym ruchu, sprawdzam limity pamięci, liczbę procesów i czas wykonania skryptów. To właśnie tutaj wychodzą przeciążenia, które z zewnątrz wyglądają jak „zła domena”, a w środku są po prostu brakującymi zasobami. Pomaga też ocena, czy serwer nie został zbyt agresywnie dociśnięty przez cache, cron albo intensywne zadanie w tle.
Po takim przeglądzie zwykle wiem już, czy trzeba poprawić kod, cofnąć wdrożenie, zwiększyć zasoby, czy zgłosić problem dostawcy hostingu. Żeby nie mylić awarii 500 z innymi kodami, warto jeszcze zobaczyć, czym różni się od sąsiednich błędów 5xx.
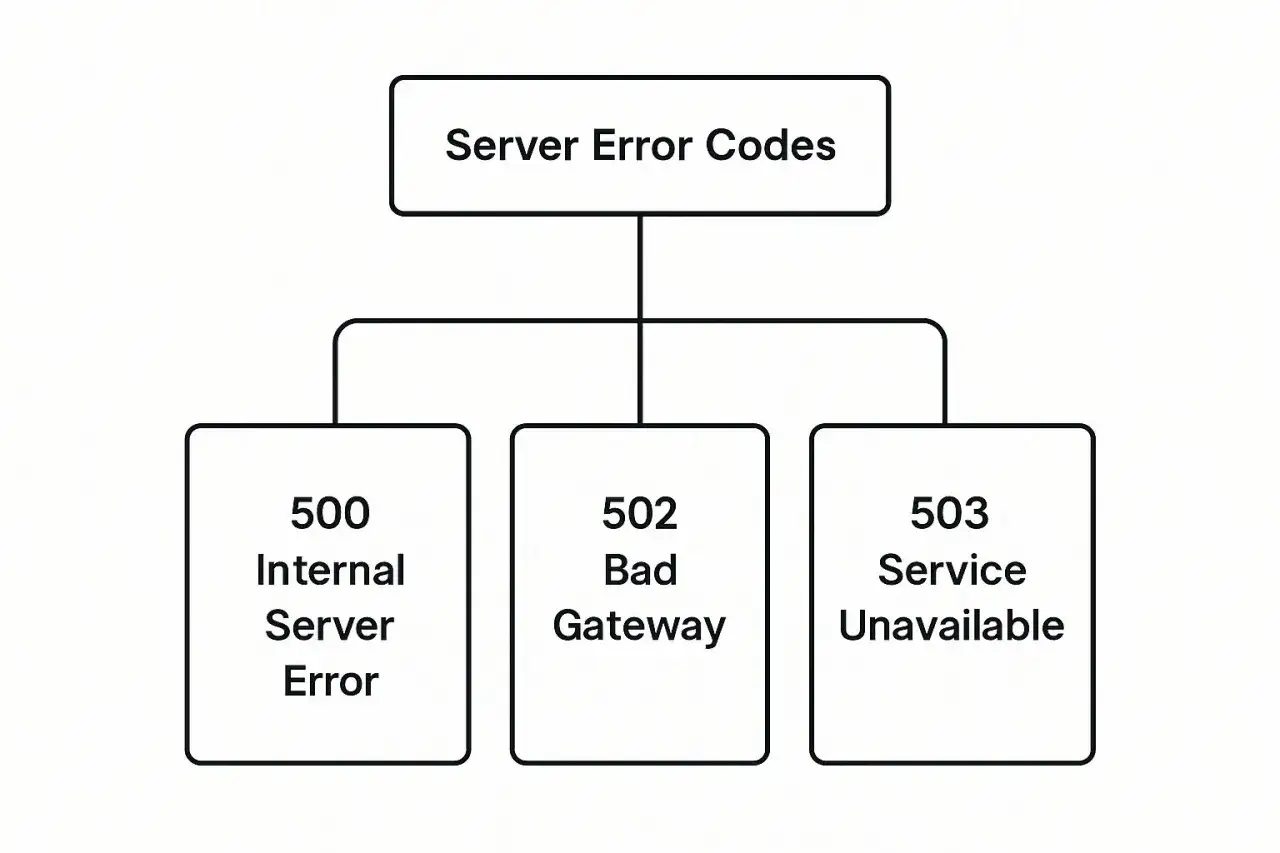
Jak odróżnić 500 od 502, 503 i 504
To rozróżnienie naprawdę ma znaczenie. Właśnie na tym etapie widać, czy problem leży w samej aplikacji, w warstwie pośredniej, czy w przeciążeniu lub timeoutach. Jeśli błędnie nazwiesz awarię, będziesz naprawiać złą warstwę.
| Kod | Co oznacza | Gdzie zwykle leży problem | Jak myślę o diagnozie |
|---|---|---|---|
| 500 | Serwer napotkał nieoczekiwany problem | Aplikacja, konfiguracja, zasoby, baza danych | Najpierw logi i ostatnie zmiany |
| 502 | Brama lub proxy dostały niepoprawną odpowiedź od upstreamu | Warstwa pośrednia, backend, reverse proxy, CDN | Sprawdzam komunikację między warstwami |
| 503 | Usługa jest tymczasowo niedostępna | Przeciążenie, konserwacja, planowany downtime | Myślę o dostępności i przepustowości |
| 504 | Brama czekała za długo na odpowiedź | Upstream, timeout, wolne zapytania, zewnętrzny serwis | Patrzę na czas odpowiedzi i wąskie gardła |
Jeżeli awaria jest planowana, lepszy bywa kod 503 niż 500, bo jasno komunikuje tymczasową niedostępność. To prosty detal, ale dla użytkownika i dla robotów wyszukiwarek ma znaczenie. Z tego powodu przechodzę teraz do wpływu takich błędów na SEO i na ruch z wyszukiwarki.
Jak ograniczyć wpływ błędów 5xx na SEO i użytkowników
Google Search Central wyjaśnia, że błędy 5xx skłaniają Googlebota do czasowego spowolnienia crawlowania, a uporczywe problemy mogą prowadzić do usuwania adresów z indeksu. Nie dzieje się to od jednego krótkiego incydentu, ale jeśli awarie wracają regularnie, wyszukiwarka zaczyna traktować stronę jako mniej stabilną.
W praktyce największy problem nie leży w samym kodzie, tylko w jego częstotliwości i czasie trwania. Krótki przestój można przeżyć, ale długie lub powtarzalne 500 uderza jednocześnie w użytkownika, indeksowanie i zaufanie do serwisu. Ja zwracam uwagę na trzy rzeczy: czas niedostępności, liczbę dotkniętych adresów i to, czy awaria dotyczy tylko jednej funkcji, czy całej platformy.
Jeśli masz planowany maintenance, używaj komunikatu, który mówi prawdę o stanie usługi. 503 z odpowiednim wskazaniem czasu powrotu jest uczciwszy niż 500, bo nie udaje losowej awarii. Z kolei strony, które wyglądają jak błędowe, ale zwracają 200, potrafią wpaść w problem soft 404, więc „ukrywanie” awarii nie jest żadnym rozwiązaniem.
Co wdrożyć, żeby awaria nie wracała
Największą różnicę robi nie jednorazowa naprawa, tylko proces. Jeśli chcesz realnie ograniczyć ryzyko powrotu tego samego błędu, budujesz system, który szybciej wykrywa problem i pozwala wrócić do stabilnej wersji bez paniki.
- Monitoring dostępności i 5xx - sprawdzaj stronę co 1-5 minut i ustaw alert, gdy rośnie odsetek błędów.
- Logi z identyfikatorem żądania - dzięki request ID łatwiej połączyć zgłoszenie użytkownika z konkretnym wpisem w logu.
- Staging i rollback - każda większa zmiana powinna dać się cofnąć w kilka minut.
- Ograniczenie liczby wtyczek i integracji - im mniej ruchomych elementów, tym mniejsza szansa na konflikt.
- Alerty na zasoby serwera - CPU, RAM, I/O i błędy bazy danych trzeba obserwować zanim padnie strona, a nie po fakcie.
- Jasny podział odpowiedzialności - ktoś musi wiedzieć, czy przy incydencie dzwonisz do hostingu, devów, czy do osoby od CDN i DNS.
Jeśli mam zostawić jedną praktyczną zasadę, to tę: ten błąd traktuję jak sygnał do diagnostyki warstwowej, a nie jak „problem domeny”. Gdy masz logi, monitoring i możliwość szybkiego cofnięcia zmian, większość takich awarii da się zamknąć szybko i bez zgadywania.