
Błąd 502 oznacza przerwę w komunikacji między serwerami, a niekoniecznie problem z przeglądarką. W przypadku domen najczęściej wchodzą w grę ustawienia DNS, certyfikat SSL, proxy lub niedostępny serwer źródłowy. Ja zwykle dzielę taki incydent na trzy warstwy: domenę, pośrednika i aplikację. W tym artykule pokazuję, jak rozpoznać źródło problemu, co sprawdzić najpierw i jak ograniczyć ryzyko, że sytuacja wróci przy kolejnym wdrożeniu.
Najkrótsza wersja jest taka, że problem zwykle leży po drodze do serwera źródłowego
- Błąd 502 oznacza, że pośrednik, taki jak reverse proxy, CDN albo load balancer, dostał nieprawidłową odpowiedź od backendu.
- Przy domenach najczęściej winne są rekordy DNS, certyfikat SSL, konfiguracja proxy lub sam serwer aplikacji.
- Jeśli problem dotyczy tylko jednej wersji adresu, na przykład bez
wwwalbo zwww, sprawdzam najpierw strefę DNS i przekierowania. - Gdy awaria pojawia się po migracji, często chodzi o propagację DNS, wygasły certyfikat albo stary adres IP zapisany w rekordzie.
- Najlepsza diagnoza zaczyna się od prostych testów z innej sieci, a dopiero potem przechodzi do logów i konfiguracji serwera.
Co naprawdę oznacza błąd 502, gdy w grę wchodzi domena
W praktyce przeglądarka wysyła żądanie do domeny, ale po drodze często stoi jeszcze CDN, reverse proxy albo load balancer. Jeśli ten pośrednik dostanie od serwera źródłowego odpowiedź niepełną, niepoprawną albo połączenie zostanie zerwane, pokazuje 502. Ja traktuję to jako sygnał, że problem jest w łańcuchu dostarczania odpowiedzi, a niekoniecznie w samym adresie strony.
To rozróżnienie jest ważne, bo odwiedzający widzi jeden komunikat, a przyczyny mogą być zupełnie różne. Czasem winny jest rekord A, czasem certyfikat, czasem firewall blokujący IP pośrednika, a czasem po prostu aplikacja na serwerze nie daje rady odpowiedzieć na czas.
| Kod | Co oznacza | Kiedy zwykle się pojawia |
|---|---|---|
| 502 | Pośrednik dostał nieprawidłową odpowiedź od serwera źródłowego | Awaria backendu, problem z proxy, SSL lub urwane połączenie |
| 503 | Usługa jest chwilowo niedostępna | Przeciążenie, prace serwisowe, brak zasobów |
| 504 | Pośrednik czekał za długo na odpowiedź | Timeout po stronie backendu albo zbyt wolna aplikacja |
Ja zawsze patrzę na te trzy kody razem, bo w praktyce różnica między nimi mówi, gdzie dokładnie pęka łańcuch. To prowadzi do najczęstszych przyczyn, które w domenach widzę najczęściej.
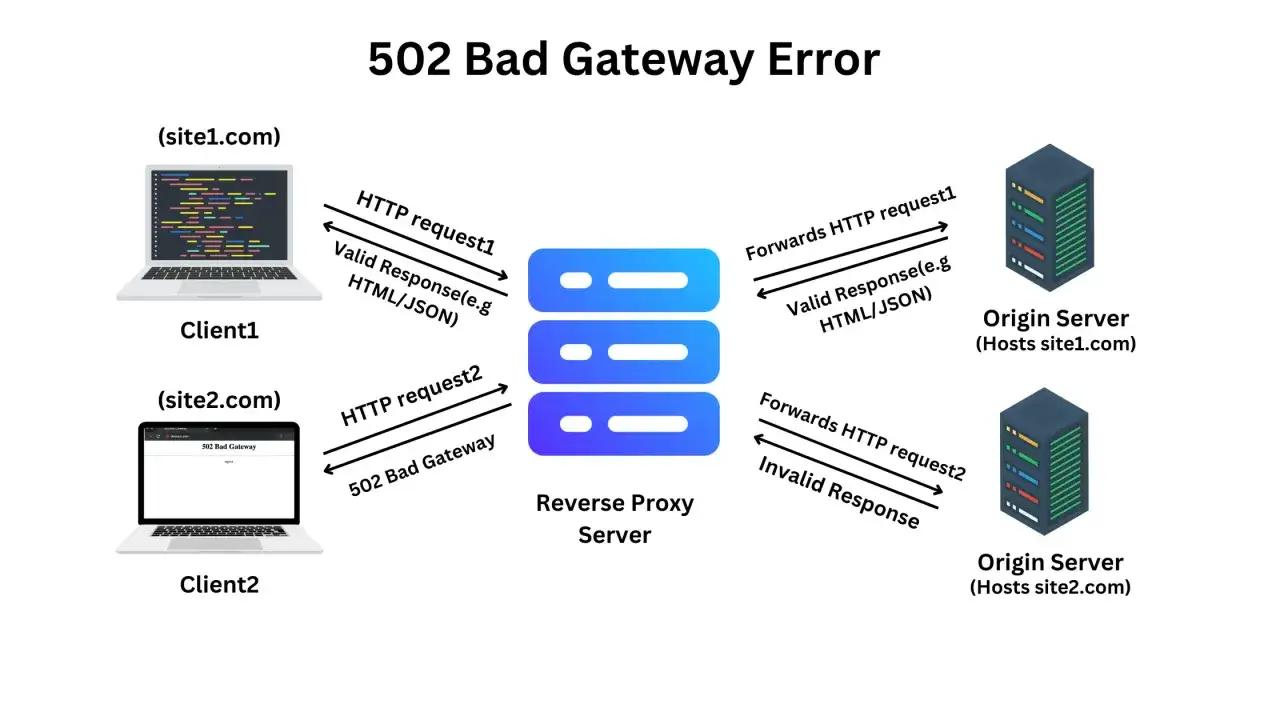
Najczęstsze przyczyny po stronie domeny i hostingu
W domenach źródło problemu bardzo często siedzi w warstwie, której na pierwszy rzut oka nie widać. Ja najpierw rozdzielam awarie na cztery grupy: DNS, pośrednik, SSL i backend. Dzięki temu szybciej wychodzi, czy trzeba ruszać rekordy domeny, czy raczej szukać problemu na serwerze.
DNS wskazuje złe miejsce
Jeśli rekordy domeny prowadzą na stary adres IP, na niedziałający serwer albo na host, który już nie odpowiada, pośrednik może zwrócić 502 mimo poprawnie wpisanej nazwy. To szczególnie częste po migracji hostingu, zmianie dostawcy albo przełączaniu środowisk z testowego na produkcyjne.
Warto też sprawdzić rekord AAAA. Jeśli serwis nie obsługuje IPv6, a domena ma aktywny, ale błędny adres IPv6, część użytkowników zobaczy problem szybciej niż inni. To jeden z tych przypadków, które potrafią wyglądać losowo, choć źródło jest całkiem konkretne.
Pośrednik nie może dogadać się z originem
Reverse proxy, CDN albo load balancer przekazują ruch dalej do serwera źródłowego, czyli tak zwanego upstream. Jeśli ten etap zawiedzie, na ekranie pojawia się 502. Przyczyną bywa zamknięty port, zły host header, blokada firewall albo reguła bezpieczeństwa, która przepuszcza przeglądarki, ale zatrzymuje ruch z infrastruktury pośredniej.
Tu często pomaga proste pytanie: czy serwer źródłowy odpowiada bezpośrednio, gdy wywołam go po IP lub z panelu diagnostycznego? Jeśli nie, problem jest po stronie backendu, a nie domeny.
SSL i TLS przerywają handshake
Jeżeli certyfikat wygasł, nie pasuje do nazwy domeny albo łańcuch certyfikacji jest niekompletny, pośrednik może uznać odpowiedź za nieprawidłową. W praktyce wygląda to jak zwykły błąd 502, choć korzeń problemu leży w negocjacji bezpieczeństwa między warstwami.
To ważne zwłaszcza przy domenach z www i bez www. Obie wersje muszą być obsługiwane spójnie, inaczej jedna może działać, a druga już nie.
Serwer źródłowy się dławi albo nie działa
Nawet poprawna domena nie pomoże, jeśli aplikacja nie odpowiada. Przeciążony PHP-FPM, padnięty proces Node.js, niedostępna baza danych albo zbyt agresywny deploy potrafią zakończyć połączenie zanim serwer wyśle poprawną odpowiedź. Dla pośrednika to nadal wygląda jak 502.
Ja w takich sytuacjach szukam najpierw korelacji z ostatnimi zmianami. Jeśli problem zaczął się po wdrożeniu, po restarcie kontenera albo po zwiększonym ruchu, prawdopodobnie nie chodzi o samą domenę, tylko o warstwę aplikacji.
Jeżeli chcesz szybko zawęzić przyczynę, najpierw ustal, czy problem dotyczy wszystkich użytkowników, czy tylko części ruchu. To prowadzi do prostszej, ale często skutecznej diagnostyki.
Jak diagnozuję problem krok po kroku
W diagnostyce działam od najtańszych i najszybszych testów do najgłębszych. Dzięki temu nie spędzam godziny na grzebaniu w aplikacji, jeśli problem siedzi w DNS albo w certyfikacie. Taki porządek naprawdę oszczędza czas, zwłaszcza przy domenach obsługujących ruch produkcyjny.
Jeśli patrzysz na to z zewnątrz
- Otwórz stronę z innej sieci, najlepiej przez dane komórkowe, a nie przez ten sam Wi-Fi, z którego korzystasz na co dzień.
- Sprawdź osobno adres z
wwwi bezwww. Jeśli jedna wersja działa, a druga nie, problem zwykle siedzi w DNS albo przekierowaniu. - Przetestuj stronę w trybie prywatnym i bez VPN. Jeśli błąd znika, podejrzewam lokalny cache DNS, rozszerzenie przeglądarki albo filtr sieciowy.
- Jeśli masz techniczne narzędzia, użyj
curl -Ialbo porównaj odpowiedzi z kilku lokalizacji. Jedna sieć potrafi maskować problem, a druga od razu go ujawnia.
Przeczytaj również: Błąd 400 - co oznacza i jak go naprawić krok po kroku?
Jeśli zarządzasz domeną lub hostingiem
- Sprawdź logi reverse proxy i logi aplikacji z czasu wystąpienia błędu. Interesują mnie zwłaszcza komunikaty o urwanych połączeniach, timeoutach i błędach handshake.
- Zweryfikuj rekordy
A,AAAAiCNAME. Ja zawsze porównuję je z aktualnym adresem originu, bo stary wpis to jeden z najprostszych sposobów na 502 po migracji. - Potwierdź, że serwer źródłowy odpowiada na właściwych portach, zwykle 80 i 443, oraz że firewall nie blokuje adresów CDN, proxy lub load balancera.
- Sprawdź certyfikat SSL, datę wygaśnięcia i zgodność nazwy domeny z certyfikatem. Błędny lub wygasły certyfikat potrafi wywołać problem, który na poziomie komunikatu wygląda identycznie jak awaria aplikacji.
- Porównaj czas awarii z ostatnim wdrożeniem, zmianą DNS albo restartem usług. Jeśli incydent zaczyna się dokładnie po zmianie, kierunek śledztwa jest zwykle bardzo jasny.
- Jeżeli zmieniałeś rekordy niedawno, daj DNS-owi czas. Propagacja potrafi potrwać od kilkunastu minut do 24 godzin, a przy bardziej opornych resolverach nawet dłużej.
Najbardziej praktyczna zasada jest prosta: najpierw oddziel problem domeny od problemu serwera, a dopiero potem wchodź w szczegóły. To naturalnie prowadzi do konfiguracji, która najczęściej wymaga korekty.
Co poprawić w DNS, certyfikacie i proxy
Jeśli diagnoza wskazuje na warstwę domeny, nie naprawiam wszystkiego naraz. Najpierw koryguję element, który faktycznie steruje ruchem, a dopiero potem wracam do dodatkowych ustawień. Przy migracjach i wdrożeniach porządek zmian robi większą różnicę niż sama liczba modyfikacji.
| Obszar | Co sprawdzić | Dlaczego to ma znaczenie |
|---|---|---|
Rekordy A i AAAA
|
Czy prowadzą do aktualnego serwera i czy IPv6 faktycznie działa | Stary lub martwy adres IP często daje 502 po przełączeniu hostingu |
CNAME dla www
|
Czy wskazuje właściwy host i nie tworzy pętli | Błędny alias potrafi zepsuć tylko jedną wersję domeny |
| Delegacja DNS | Czy domena używa właściwych serwerów nazw | Zła delegacja sprawia, że ruch trafia w nieaktualną strefę |
| SSL i TLS | Data ważności, zgodność nazwy, pełny łańcuch certyfikacji | Problem z handshake często kończy się komunikatem 502 po stronie użytkownika |
| Proxy i CDN | Host header, reguły bezpieczeństwa, pozwolenia na ruch do originu | Pośrednik musi dostać odpowiedź z dokładnie tego serwera, do którego wysłał ruch |
| TTL | Czy przed zmianą obniżono go do rozsądnego poziomu, na przykład 300 sekund | Niższy TTL przyspiesza przejście na nowe ustawienia podczas migracji |
Ja przy planowanej migracji obniżam TTL z wyprzedzeniem, zwykle 24 do 48 godzin wcześniej, a po ustabilizowaniu ruchu wracam do normalnych wartości, na przykład 3600 sekund. Dzięki temu zmiany rozchodzą się szybciej, ale nie robię z DNS-a niepotrzebnego chaosu. Jeśli serwis nie obsługuje IPv6, wolę usunąć wadliwy rekord AAAA niż liczyć, że sam się naprawi.
To wszystko wygląda prosto na papierze, ale w praktyce wiele osób wpada w te same pułapki. Właśnie one najczęściej wydłużają czas naprawy.
Najczęstsze błędy, które opóźniają naprawę
- Zmiana DNS, certyfikatu i konfiguracji aplikacji jednocześnie, bez możliwości ustalenia, co naprawdę pomogło albo zaszkodziło.
- Skupienie się na czyszczeniu cache przeglądarki zamiast na sprawdzeniu logów serwera i odpowiedzi originu.
- Ignorowanie rekordu
AAAA, mimo że problem występuje tylko dla części użytkowników. - Zakładanie, że 502 oznacza zawsze to samo, chociaż czasem winny jest proxy, a czasem sam backend.
- Brak rollbacku, czyli planu cofnięcia ostatniej zmiany, jeśli nowa konfiguracja zacznie generować błędy.
- Testowanie tylko jednej wersji domeny, na przykład wyłącznie z
www, gdy użytkownicy korzystają również z domeny głównej.
Największą oszczędność czasu daje konsekwencja: jeden test, jedna zmiana, jeden log. Jeśli po każdej poprawce od razu sprawdzam efekt, dużo szybciej dochodzę do przyczyny. Z tego samego podejścia korzystam też wtedy, gdy chcę ograniczyć ryzyko powrotu problemu po wdrożeniu.
Jak ograniczyć ryzyko powrotu problemu po wdrożeniu
Jeśli domena ma działać stabilnie, nie wystarczy jednorazowo naprawić 502. Ja zawsze myślę o całej ścieżce ruchu, bo to ona decyduje, czy błąd wróci przy następnym deployu, rotacji certyfikatu albo zmianie DNS.
- Włącz monitoring z co najmniej dwóch lub trzech lokalizacji, żeby widzieć, czy awaria jest globalna, czy tylko regionalna.
- Ustaw alerty po kilku kolejnych nieudanych odpowiedziach, a nie po pojedynczym wahnięciu.
- Dodaj prosty endpoint zdrowia dla backendu, żeby proxy mogło szybko stwierdzić, czy aplikacja żyje.
- Wdrażaj zmiany etapami, jeśli to możliwe, zamiast przełączać cały ruch naraz.
- Automatyzuj odnawianie certyfikatów i ustaw przypomnienie z wyprzedzeniem, najlepiej około 30 dni przed wygaśnięciem.
- Przechowuj konfigurację DNS i proxy w wersjonowanym repozytorium, bo wtedy łatwiej wrócić do poprzedniego stanu.
- Przy większych migracjach zostaw stary serwer jako zapasowy punkt odniesienia, dopóki nowy nie przejdzie testów ruchu i logów.
W dobrze utrzymanej domenie błąd 502 nie powinien być tajemnicą, tylko krótkim incydentem, który da się szybko zlokalizować. Jeśli pilnujesz DNS, SSL, proxy i logów w jednym porządku, diagnostyka przestaje być zgadywaniem, a zaczyna być normalnym procesem technicznym.