HTTP jest fundamentem komunikacji w sieci: to nim przeglądarka, aplikacja mobilna, serwer API i pośrednie warstwy infrastruktury wymieniają dane. W praktyce ważniejsze od samej definicji jest to, jak ten protokół zachowuje się pod obciążeniem, jak współpracuje z cache i proxy oraz kiedy trzeba przejść na bezpieczniejsze i wydajniejsze warianty transmisji. Poniżej porządkuję temat od podstaw aż po realne konsekwencje dla stron, API i infrastruktury.
Najważniejsze rzeczy o HTTP, które porządkują cały obraz
- HTTP działa w warstwie aplikacji i opiera się na modelu żądanie-odpowiedź.
- Sam protokół jest bezstanowy, ale sesje i logowanie tworzą stan po stronie aplikacji.
- Metody, nagłówki i kody stanu decydują o tym, jak serwer interpretuje intencję klienta.
- HTTPS to HTTP zabezpieczone przez TLS, czyli szyfrowanie, integralność i weryfikację serwera.
- HTTP/2 i HTTP/3 poprawiają wydajność, ale nie zmieniają podstawowej semantyki komunikacji.
- Najwięcej błędów w projektach nie wynika z samego protokołu, tylko z jego złego użycia.
Czym jest HTTP w architekturze sieci
Ja patrzę na HTTP przede wszystkim jak na język kontraktu między klientem a serwerem. Klient mówi, czego potrzebuje, serwer odpowiada tym, co ma, a cały ruch odbywa się w warstwie aplikacji, nad warstwą transportową i sieciową. W praktyce oznacza to, że HTTP nie przesyła „strony” jako jednego bloku, tylko serię wiadomości opisujących zasób, nagłówki, sposób interpretacji danych i wynik operacji.
To podejście jest proste, ale bardzo skuteczne. Ten sam mechanizm obsługuje zwykłe strony WWW, API, pobieranie plików, autoryzację, przekierowania, cache i integracje między systemami. Warto też pamiętać, że po drodze często pojawiają się pośrednicy: reverse proxy, CDN, cache, load balancer albo WAF. Nie każdy request trafia bezpośrednio do serwera origin, więc w analizie problemów sieciowych trzeba patrzeć szerzej niż tylko na aplikację.HTTP jest też bezstanowy, czyli sam protokół nie pamięta poprzednich żądań. Jeśli aplikacja „pamięta” użytkownika, robi to zwykle przez cookies, tokeny sesyjne albo inne mechanizmy po stronie serwera. To ważne rozróżnienie, bo początkujący często mylą stan aplikacji ze stanem protokołu. Z tego miejsca naturalnie przechodzę do tego, jak wygląda pojedyncza wymiana wiadomości w praktyce.
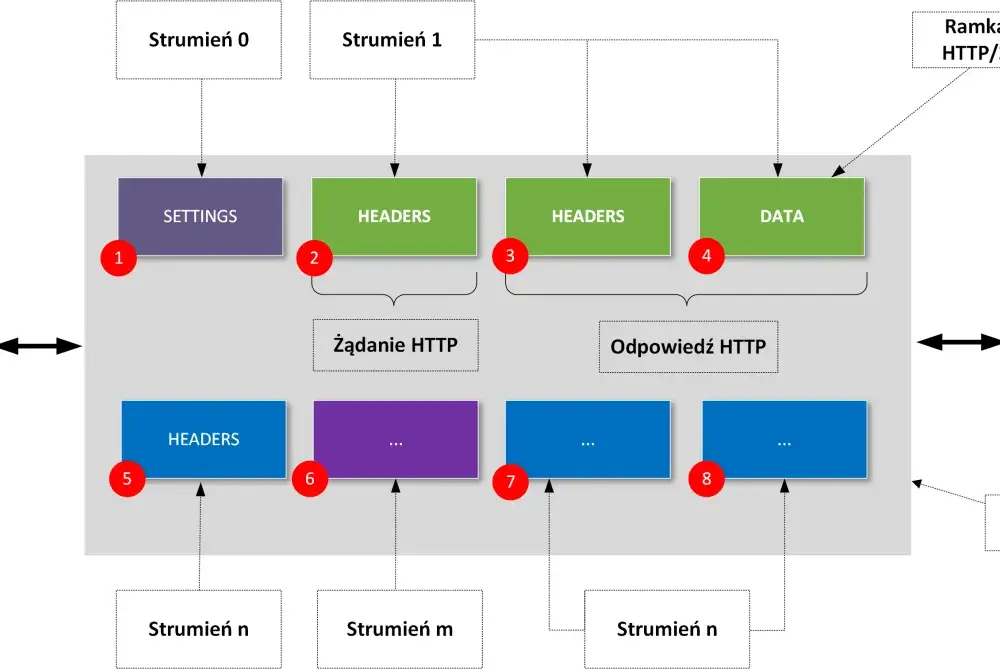
Jak wygląda pojedyncza wymiana żądania i odpowiedzi
Typowa wymiana zaczyna się od tego, że klient ustala adres zasobu, a następnie nawiązuje połączenie z odpowiednim hostem. W zależności od wersji protokołu może to być klasyczny TCP, albo QUIC w HTTP/3. Jeśli używany jest HTTPS, dochodzi jeszcze negocjacja TLS, czyli warstwy odpowiedzialnej za szyfrowanie i uwierzytelnienie serwera.
- Klient wybiera zasób, na przykład stronę, endpoint API albo plik.
- Wysyła żądanie składające się z linii startowej, nagłówków i opcjonalnego ciała.
- Serwer analizuje metodę, nagłówki, autoryzację i treść żądania.
- W odpowiedzi zwraca kod stanu, nagłówki i opcjonalne dane.
- Przeglądarka lub klient API interpretuje wynik i podejmuje dalsze kroki, na przykład dociąga kolejne zasoby.
W samym żądaniu i odpowiedzi kryją się wszystkie informacje, które później widzi deweloper w narzędziach diagnostycznych. Dlatego jeśli coś działa wolno albo błędnie, ja zawsze zaczynam od sprawdzenia, co dokładnie zostało wysłane i co dokładnie wróciło, zamiast od zgadywania przyczyny. Z tego miejsca przechodzę do elementów, które nadają temu ruchowi znaczenie: metod, nagłówków i statusów.
Metody HTTP mówią serwerowi, co chcesz zrobić
Metoda jest pierwszą informacją o intencji klienta. To właśnie ona mówi serwerowi, czy chodzi o odczyt danych, utworzenie zasobu, częściową zmianę, usunięcie czy sprawdzenie możliwości komunikacji. Gdy projektuję API, metoda jest dla mnie punktem wyjścia, bo źle dobrana metoda psuje cache, utrudnia retry i wprowadza chaos semantyczny.
| Metoda | Do czego służy | Najważniejsza cecha | Gdzie łatwo popełnić błąd |
|---|---|---|---|
| GET | Pobranie reprezentacji zasobu | Bezpieczna, idempotentna i zwykle cache'owalna | Nie powinna zmieniać stanu po stronie serwera |
| HEAD | Jak GET, ale bez ciała odpowiedzi | Przydatna do testów, nagłówków i kontroli cache | Bywa pomijana, mimo że jest bardzo użyteczna |
| POST | Przesłanie danych, często utworzenie lub uruchomienie operacji | Nie jest idempotentna z założenia | Stosowana do wszystkiego, nawet do zwykłego odczytu |
| PUT | Pełna podmiana zasobu | Idempotentna | Mylenie z POST i częściową aktualizacją |
| PATCH | Częściowa modyfikacja zasobu | Semantyka zależy od implementacji | Zakładanie, że zachowuje się tak samo w każdym API |
| DELETE | Usunięcie zasobu | Idempotentna | Brak obsługi powtórzeń i błędne statusy odpowiedzi |
| OPTIONS | Sprawdzenie dostępnych możliwości komunikacji | Ważna przy CORS i preflight | Ignorowana, choć dla przeglądarek bywa krytyczna |
W praktyce trzy pojęcia robią największą różnicę: safe, idempotent i cacheable. Safe oznacza, że metoda nie powinna zmieniać stanu serwera. Idempotentna znaczy, że wielokrotne wysłanie tego samego żądania daje ten sam skutek. Cacheable oznacza, że odpowiedź może zostać zapamiętana i użyta ponownie, co zwykle dotyczy przede wszystkim GET i HEAD. To właśnie te właściwości decydują, czy można bezpiecznie retry'ować żądanie i czy warstwa pośrednia ma sensownie je cachować.
Kiedy metody są dobrze dobrane, łatwiej też czytać odpowiedzi serwera. Tu wchodzą nagłówki i kody stanu, które opowiadają, co się stało i dlaczego.
Nagłówki i kody stanu opisują kontekst oraz wynik
Nagłówki przenoszą metadane: typ treści, zasady cache, autoryzację, ciasteczka, kompresję, warunki dostępu albo adres przekierowania. W HTTP/1.x nazwy nagłówków są nieczułe na wielkość liter, a w HTTP/2 i nowszych zwykle widzisz je zapisane małymi literami w narzędziach deweloperskich. Do najważniejszych pól, które regularnie sprawdzam, należą Content-Type, Accept, Authorization, Cache-Control, ETag, Location, Set-Cookie, Vary i Retry-After.
| Kategoria | Przykłady | Jak to odczytuję |
|---|---|---|
| 1xx | 100, 101, 103 | Odpowiedź informacyjna, jeszcze nie wynik końcowy |
| 2xx | 200, 201, 204, 206 | Żądanie się udało |
| 3xx | 301, 302, 307, 308 | Trzeba przejść pod inny adres albo zachować metodę podczas przekierowania |
| 4xx | 400, 401, 403, 404, 409, 429 | Problem po stronie klienta, danych albo uprawnień |
| 5xx | 500, 502, 503, 504 | Problem po stronie serwera lub warstwy pośredniej |
- 401 oznacza brak poprawnego uwierzytelnienia, więc klient powinien się zalogować lub dosłać dane dostępu.
- 403 oznacza, że serwer rozumie żądanie, ale nie pozwala go wykonać.
- 429 sygnalizuje limitowanie liczby żądań i ma znaczenie przy API publicznych oraz integracjach.
- 103 Early Hints pozwala wcześniej rozpocząć preload lub preconnect, zanim dojdzie pełna odpowiedź.
Najwięcej zamieszania widzę wtedy, gdy aplikacja zwraca kod 200, ale w treści umieszcza komunikat o błędzie. To psuje monitoring, logikę klienta i obsługę retry. Dużo lepiej jest dobrać właściwy status niż maskować problem ładnym JSON-em. Kiedy ten fundament jest już ustawiony, można sensownie rozmawiać o bezpieczeństwie transmisji.
HTTP i HTTPS nie różnią się tylko jedną literą
HTTPS to HTTP przenoszone przez TLS. Ten dodatkowy mechanizm daje trzy rzeczy, które w sieci są krytyczne: szyfrowanie, integralność danych i weryfikację tożsamości serwera. W praktyce oznacza to, że ktoś podsłuchujący ruch nie widzi treści, nie powinien jej móc zmienić po drodze i nie powinien podszyć się pod właściwy serwer bez wykrycia.
W codziennej pracy zakładam, że port 80 kojarzy się z ruchem nieszyfrowanym, a port 443 z połączeniami zabezpieczonymi, choć infrastruktura może być skonfigurowana inaczej. Sama obecność certyfikatu nie rozwiązuje jednak wszystkiego. HTTPS chroni transmisję, ale nie naprawia błędów logiki aplikacji, złej autoryzacji, podatności XSS ani wycieków danych do logów.
Jest jeszcze jeden praktyczny szczegół: uwierzytelnianie podstawowe i inne mechanizmy przesyłające dane logowania powinny działać przez TLS. Bez tego hasło albo token trafia do sieci w postaci, którą łatwo przechwycić. Dlatego w nowym projekcie nie traktuję HTTPS jako dodatku, tylko jako domyślny sposób komunikacji. Gdy to jest ustalone, można uczciwie porównać wersje samego protokołu i zobaczyć, co faktycznie zmieniają.
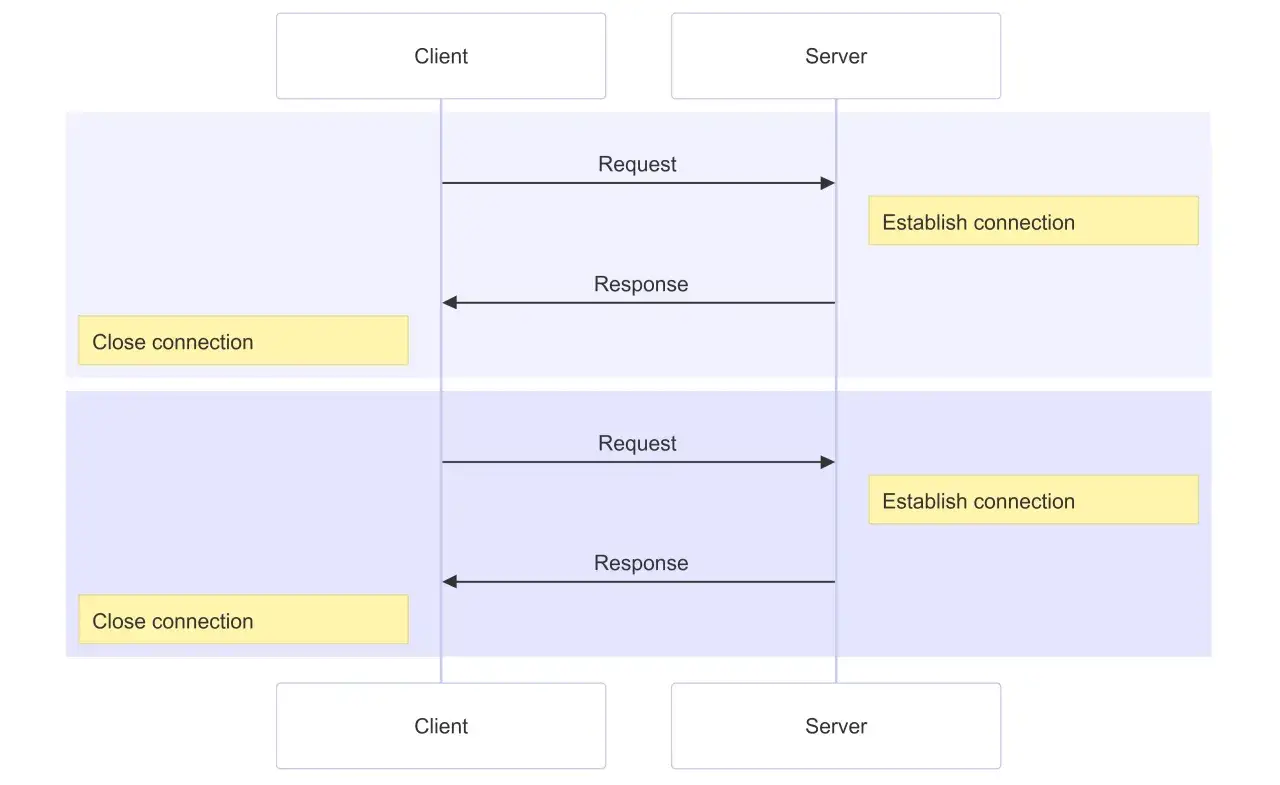
Czym różnią się HTTP/1.1, HTTP/2 i HTTP/3
Semantyka HTTP pozostaje ta sama, ale zmienia się sposób przenoszenia wiadomości przez sieć. To ważne rozróżnienie, bo użytkownik końcowy zwykle widzi ten sam adres i ten sam zasób, ale pod spodem protokół zachowuje się inaczej. Ja traktuję wersję HTTP jako decyzję o wydajności, kompatybilności i odporności na warunki sieciowe, a nie jako marketingową naklejkę.
| Wersja | Transport | Co daje w praktyce | Ograniczenia |
|---|---|---|---|
| HTTP/1.1 | Najczęściej TCP | Najszersza kompatybilność, prosty model, długie połączenia | Większy narzut przy wielu zasobach i słabsza efektywność przy dużej liczbie równoległych żądań |
| HTTP/2 | TCP z warstwą TLS w praktyce najczęściej | Multiplexing, kompresja nagłówków, lepsze wykorzystanie połączenia | Przy stratach pakietów nadal ogranicza go TCP |
| HTTP/3 | QUIC over UDP | Lepsza odporność na opóźnienia i utraty, niezależne strumienie, nowocześniejsza kontrola transportu | Wymaga wsparcia po stronie serwera, CDN, firewalla i klienta |
Po tej warstwie technicznej zostaje jeszcze najważniejsze pytanie: jakie błędy naprawdę psują pracę z HTTP w projektach i jak ich uniknąć?
Najczęstsze błędy, które widzę w projektach webowych i API
- Używanie POST do wszystkiego - wtedy znika sens semantyki metod, a retry i cache stają się trudniejsze do kontrolowania.
- Wysyłanie zmian przez GET - to zły wzorzec, bo GET powinien służyć do odczytu, a nie do operacji zmieniających stan.
- Maskowanie błędów kodem 200 - klient, monitoring i debugowanie tracą wtedy wiarygodny sygnał o problemie.
-
Ignorowanie cache - brak
Cache-Control,ETagiVaryoznacza zbędne obciążenie originu i gorszą wydajność. - Brak idempotencyjności tam, gdzie jest potrzebna - przy awariach i ponownych próbach łatwo o duplikaty zamówień lub zapisów.
- Trzymanie sekretów w adresie URL - query stringi lądują w logach, historii przeglądarki i narzędziach analitycznych.
- Pomijanie OPTIONS i CORS - dla aplikacji uruchamianych w przeglądarce to często twarda blokada jeszcze przed wejściem do logiki biznesowej.
Jeśli miałbym wskazać jedną rzecz, która daje najszybszą poprawę, byłoby to uporządkowanie statusów, metod i cache. Dopiero później warto optymalizować transport, bo bez poprawnej semantyki nawet najszybsza wersja protokołu nie uratuje źle zaprojektowanego API. To prowadzi mnie do krótkiego zamknięcia tematu z praktycznym naciskiem.
Co zostaje z HTTP, gdy odfiltrujesz skróty myślowe
HTTP jest prosty tylko na pierwszy rzut oka. Gdy zaczynasz pracować z nim świadomie, widać, że to zestaw precyzyjnych reguł: metoda mówi o intencji, nagłówki niosą kontekst, status koduje wynik, a wersja protokołu wpływa na wydajność i zachowanie w realnej sieci. Właśnie dlatego ten temat jest tak ważny w projektach webowych, API i systemach rozproszonych.
- Jeśli projektujesz odczyt danych, trzymaj się GET lub HEAD i pozwól cache robić swoją pracę.
- Jeśli zmieniasz stan, dobierz metodę do semantyki operacji zamiast używać jednej metody „do wszystkiego”.
- Jeśli przesyłasz dane wrażliwe, traktuj TLS jako standard, nie opcję.
- Jeśli coś działa wolno, najpierw sprawdzaj nagłówki, statusy i pośredników, a dopiero potem samą aplikację.
W dobrze zaprojektowanej usłudze to właśnie te decyzje robią różnicę między ruchem, który „jakoś działa”, a ruchem przewidywalnym, bezpiecznym i łatwym do utrzymania pod obciążeniem.